

اذا قمت في عملك او خلال دراستك ببناء نموذح آله وكانت النتيجة للنموذج غير دقيقة فأول مايبدر الى ذهنك هو ليش ماأجلس اعدل في Hyperparameters للنموذج لزيادة من دقته, لكن سوء هذا النموذج يكمن في مكان آخر.
تخيل أنك تستطيع تحسين جودة البيانات نفسها، بدلاً من التعامل معها كشيء ثابت لا يتغير. هذا هو جوهر الذكاء الاصطناعي المتمركز حول البيانات (DCAI)، وهو البحث في طرق لتحسين مجموعات البيانات، مما يؤدي في كثير من الأحيان إلى قفزة نوعية في أداء تطبيقات التعلّم الآلي العملية.
صحيح ان هذا ليس بشئ جديد فعلماء البيانات المهرة لطالما مارسوا هذا التحسين يدويًا بالاعتماد على التجربة والحدس وهذا ليس بشئ جديد، لكن DCAI يرتقي بهذا المفهوم إلى مستوى جديد، حيث يتعامل مع تحسين البيانات كنهج منظم ودقيق.
الكم ام الكيف؟
في معظم حالات استخدام التعلّم الآلي، ليس من العملي بناء نماذج تعتمد على مجموعات بيانات ضخمة للغاية، مثل الملايين من المشاهدات (observations)، وذلك ببساطة لأن هذا الحجم من البيانات غير متوفر. هذا يعني أن الإمكانات الكاملة للتعلّم الآلي في حل المشكلات قد يتم تجاهلها أحيانًا بحجة أن مجموعة البيانات المتاحة صغيرة جدًا.
لكن ماذا لو استطعنا استخدام التعلّم الآلي لحل المشكلات استنادًا إلى مجموعات بيانات أصغر بكثير، حتى أقل من 100 مشاهدة؟ هذا أحد التحديات التي يحاول الذكاء الاصطناعي المتمركز حول البيانات DCAI التغلب عليها من خلال جمع البيانات وهندستها بشكل منظم.
في معظم حالات استخدام التعلّم الآلي، الخوارزمية التي تحتاجها موجودة بالفعل. ما يهم حقًا هو جودة بيانات الإدخال (x) وتسميات المتغير التابع (y). فلو اخذنا على سبيل المثال من موقع labelerrors بعض التوسيمات الخاظئة في قواعد البيانات المنتشرة والمستخدمة في كثير من النماذج المدربة سابقُا سنجد العديد من الاخطاء في التوسيم.
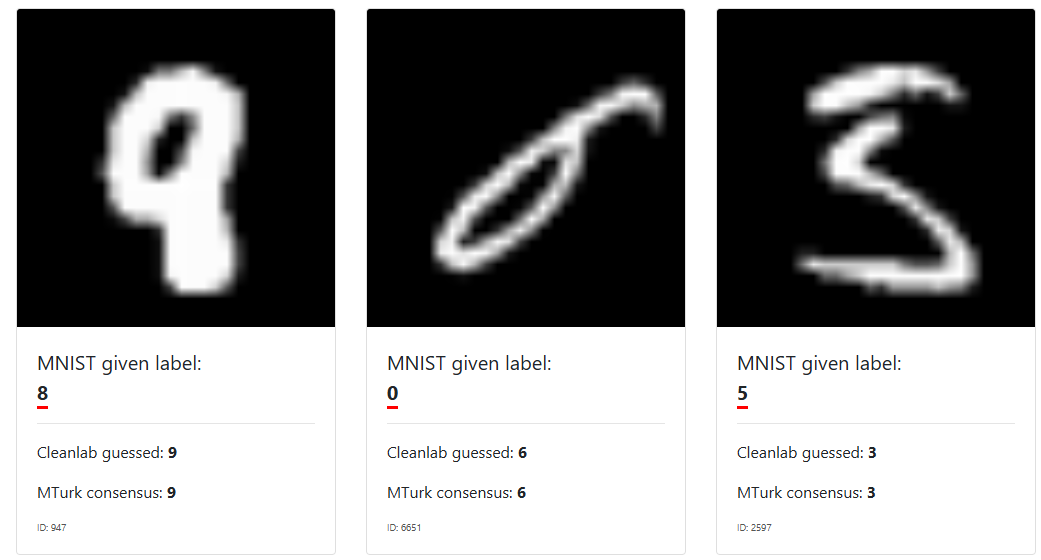
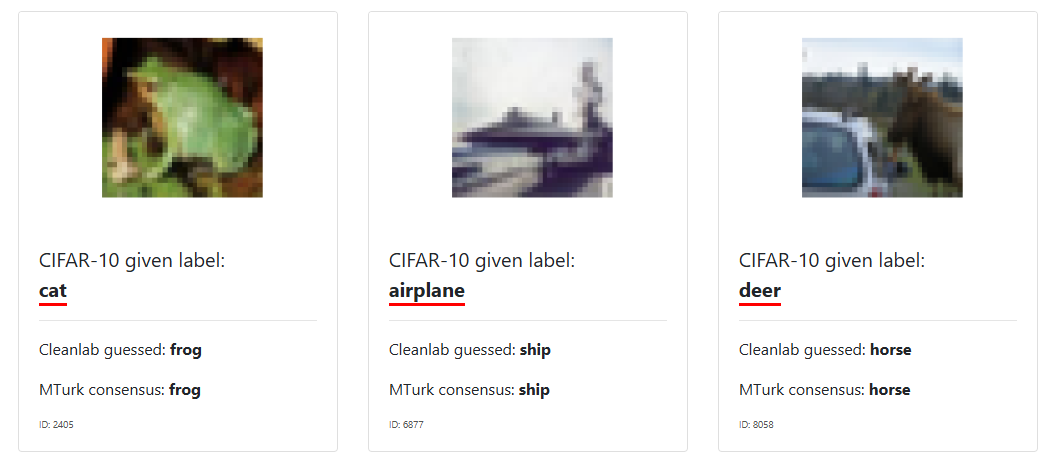
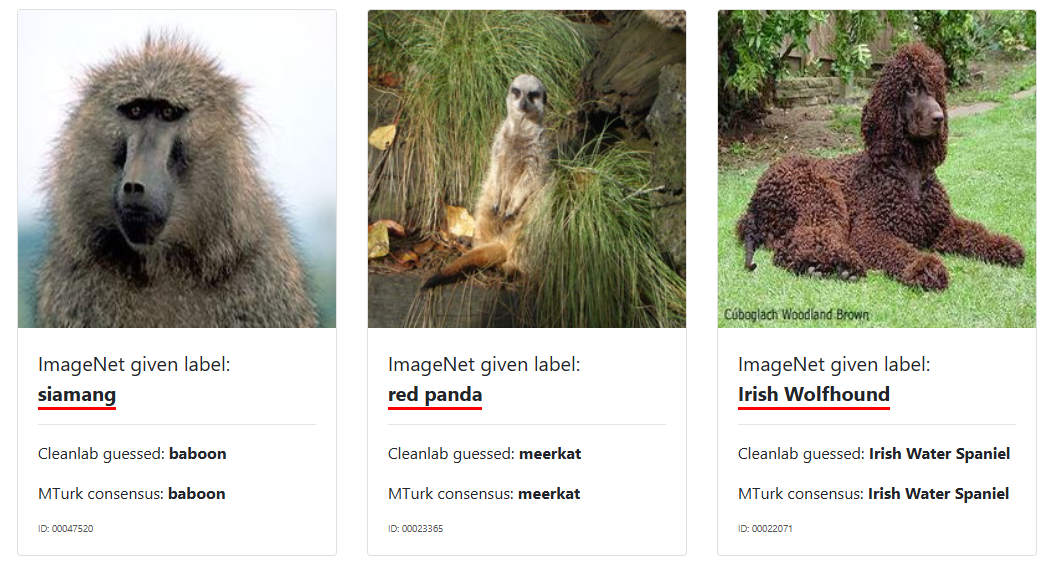
مع وجود هذه الأخطاء حاول منتجي ومطوري هذه النماذج التعامل مع الضوضاء في مجموعة البيانات عن طريق جمع أكبر قدر ممكن من البيانات لموازنة الشذوذ.
معركة البيانات مقابل النموذج
في بداية حديثنا تكلمنا انه لا يمكن معاملة البيانات معاملة الجماد والتركيز فقط على ضبط متغيرات النموذج, ربما اغادة النظر ومراجعة بيانات التدريب يقوم بتحسين النموذج بشكل لا يمكن لك تحقيقة من حلال اعادة التدريب والانتظار حتى تظهر نتائجة. فالبيانات في نهج Data-Centric هي الوقود والمحرك الرئيسي للذكاء الاصطناعي.
على سبيل المثال العديد من الأبحاث في مجال اللغات الطبيعية دربوا نماذج تتفوق على اداء نماذج دُربت على بيانات ضخة باستخدام فقط عينة قليلة من البيانات. وايضُا ذكر دكتور أندرو نج في “A Chat with Andrew on MLOps: From Model-centric to Data-centric AI” مقطع منشور على اليوتيوب, ان في أحد المشاريع الي عمل عليها سابقُا, قاموا باخذ احد النماذج وقاموا بعمل تعديلات علة نفس النموذج بدون الاقتراب من البيانات وكانت نتيجة التغير 0% في دقة النموذح, وبعد عملهم على البيانات بنفسها لمدة اسبوعين زادت الدقة للنموذج +16.9 حيث وصلت الى 93.1%. في الاسفل صورة توضح التغييرات التي عملوها:
| Steel Defect Detection | Solar Panel | Surface Inspection | |
|---|---|---|---|
| الأساس | 76.2% | 75.68% | 85.05% |
| التركيز على النموذج | +0% | +0.04% | +0.00% |
| التركيز على البيانات | +%16.9 | +3.06% | +0.4% |
وقد ذكر اندرو خلال كلامه ان “البيانات هي غذاء نماذج الذكاء الاصطناعي”. الان وبعد الحديث عن اهمية البيانات المعروفة سلفا للجميع! كيف ممكن كمهندسي ذكاء او علماء بيانات ان نتاكد من ان البيانات لدينا قابلة لتدريب نموذج ةاعطاء نتائج مرضية. سنقوم بتقسيم هذه الى عدة خطوات او طرق:
تقنيات تحسين البيانات
- تنقيح البيانات.
- توسيم البيانات.
- تحديد وإزالة التحيز
تنقيح البيانات.
كعالم بيانات او محلل بيانات اكثر مايستدعي جهد كبير منك وجل وقتك هو عملية تنظيف البيانات لملائمتها لتحليلاتك, في بعض الأوقات تأخذ البيانات 80% من الوقت المحدد لهذه الدراسة او لهذا المشروع, لأن هذا العمل يترتب عليه مجموعة من العمليات الهادفة إلى تصحيح أو إزالة البيانات الغير صحيحة، غير المكتملة، غير الصالحة، المتحيزة، غير المتسقة، القديمة، أو المعطوبة.
جودة البيانات هي مدى ملاءمة البيانات للاستخدام المقصود منها. ويمكن تقييم جودة البيانات من خلال عدة معايير، ويطلق عليها الأبعاد الستة لجودة البيانات ويمكن توضبحها في عدة نقاط: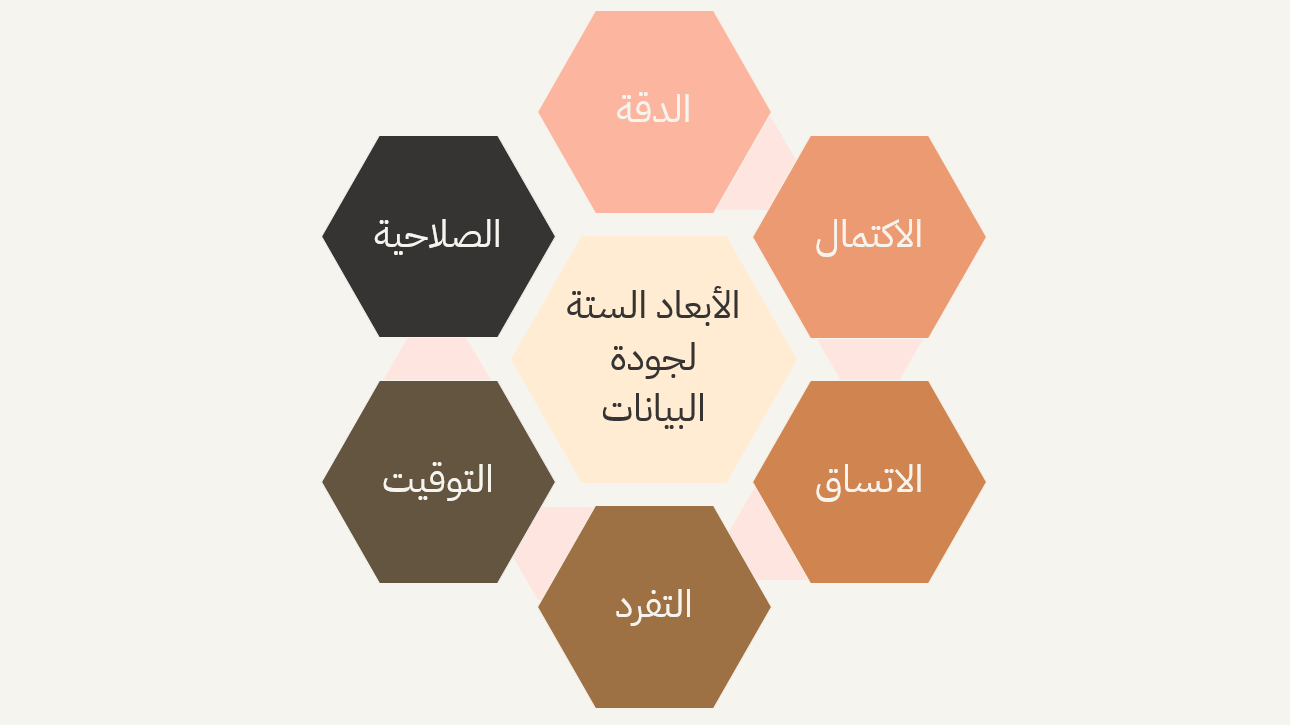
- الدقة: مدى صحة البيانات وخلوها من الأخطاء.
- الاكتمال: مدى احتواء البيانات على جميع المعلومات الضرورية.
- الاتساق: مدى توافق البيانات مع بعضها البعض وعدم وجود تناقضات.
- التفرد: مدى عدم تكرار البيانات وعدم وجود سجلات مكررة.
- التوقيت: مدى حداثة البيانات وملاءمتها للفترة الزمنية المطلوبة.
- الصلاحية: مدى توافق البيانات مع القواعد والمعايير المحددة.
كل من هذه الأبعاد تحمل خلفها مفاهيم وتقاصيل خاصة لها, لكن سنقوم في هذا الجانب من المقالة باعطاء توضيح بسيط مع مثال على كل جانب.
الدقة
هي أهم أبعاد جودة البيانات. فإذا كانت البيانات غير دقيقة، فإنها ستؤدي إلى قرارات خاطئة. ويمكن ضمان دقة البيانات من خلال عمليات التحقق والتدقيق. ففي الوقت الحالي ومع التحول الرقمي الكبير الحاصل والرقمنة للبيانات وموائمتها قد يحصل اخطاء هذه الاخطاء قد تنقلها بالطبع الى نموذج الالة الخاص بك!
الاكتمال
يجب أن تحتوي البيانات على جميع المعلومات الضرورية لاتخاذ القرارات. ويمكن ضمان اكتمال البيانات من خلال تحديد جميع الحقول الإلزامية وجمع البيانات من جميع المصادر ذات الصلة. سنستخدم أربعة أمثلة تشرح الأنواع المختلفة لمشكلات جودة اكتمال البيانات:
- السجل نفسه مفقود: هذا يعني أن السجل بالكامل غير موجود في قاعدة البيانات، مما يجعل البيانات غير كاملة.
في سجلات الموظفين في شركة، لا يوجد أي سجل لموظف جديد تم تعيينه مؤخرًا. هذا يعني أن بيانات الموظف غير موجودة بالكامل في النظام، مما يجعل من الصعب على الشركة تتبع أدائه أو احتساب راتبه. - قيمة مفقودة في سمة: هنا، السجل موجود ولكن إحدى سماته (مثل الاسم أو العنوان) لا تحتوي على قيمة.
في قاعدة بيانات العملاء لبنك، يوجد سجل لعميل جديد، لكن حقل “رقم الهاتف” فارغ. هذا يعني أن البنك لا يمكنه التواصل مع العميل عبر الهاتف، مما يعيق تقديم الخدمات له.

- قيمة مرجعية مفقودة: يحدث هذا عندما يشير سجل إلى سجل آخر غير موجود، مما يؤدي إلى عدم اكتمال البيانات.
في نظام إدارة المستشفى، يشير سجل مريض إلى رقم غرفة غير موجود في قاعدة بيانات الغرف. هذا يعني أن نظام المستشفى لا يمكنه تحديد مكان المريض، مما قد يؤدي إلى تأخير في تقديم الرعاية الطبية. في الجدول التالي توضيج لهذا الخلل, فلا يوجد في المستشفى على سبييل المثال غرفة بالرقم 3

اقتطاع البيانات: في هذه الحالة، يتم قطع جزء من البيانات بسبب قيود في حجم الحقل أو بسبب أخطاء في النظام.اكثر حالة مسبببه لهذا الاقتطاع هو ETL وهو استخراج البيانات من مصادر متعدده واتحويلها وتحمليها في قاعدة بيانات موجدة, خلال هذا النقل يحدث استقطاع للبيانات بشكل غير مقصود
في نموذج تسجيل عبر الإنترنت، يطلب من المستخدم إدخال اسمه الكامل في حقل يتسع لـ 20 حرفًا فقط. إذا كان اسم المستخدم يتجاوز هذا الحد، فسيتم قطعه، مما يؤدي إلى تسجيل اسم غير كامل. هذا قد يسبب مشاكل في التعرف على المستخدم أو التواصل معه.
الاتساق
الاتساق في جودة البيانات يشير إلى الدرجة التي تتوافق بها البيانات أو تظل موحدة عبر مجموعات بيانات مختلفة أو بالمقارنة مع مجموعة بيانات مرجعية.
أمثلة على أبعاد اتساق البيانات
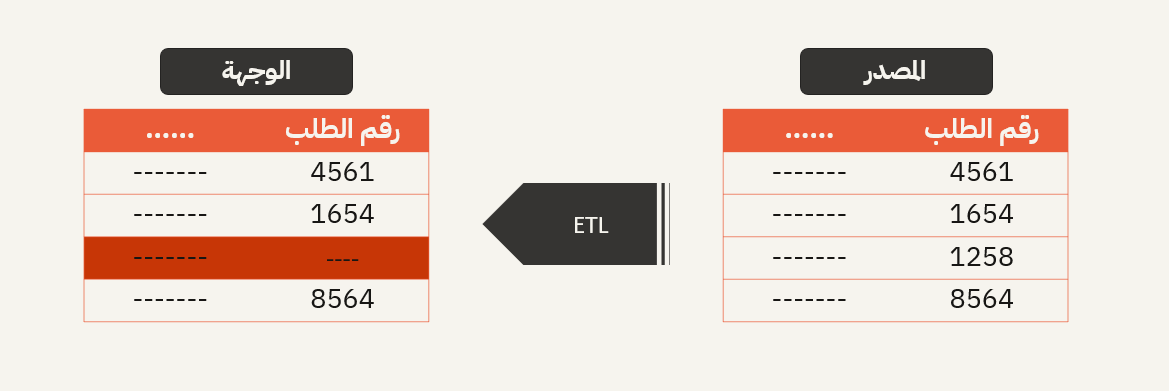
- اتساق بيانات مستوى السجل عبر المصدر والوجهة
ضمان توافق البيانات المحملة من نظام ما مع النظام المصدر. على سبيل المثال، يوجد سجل مبيعات لمعاملة معينة في قاعدة بيانات المصدر ولكنه مفقود في قاعدة بيانات الوجهة بعد ترحيل البيانات.
- اتساق بيانات مستوى السمة عبر المصدر والوجهة
عندما توجد السجلات في كل من المصدر والوجهة ولكن لا تتطابق سماتها. على سبيل المثال، يوجد سجل الموظف في كل من نظام الموارد البشرية ونظام الرواتب، ولكن تفاصيل الراتب غير صحيحة في نظام الرواتب.
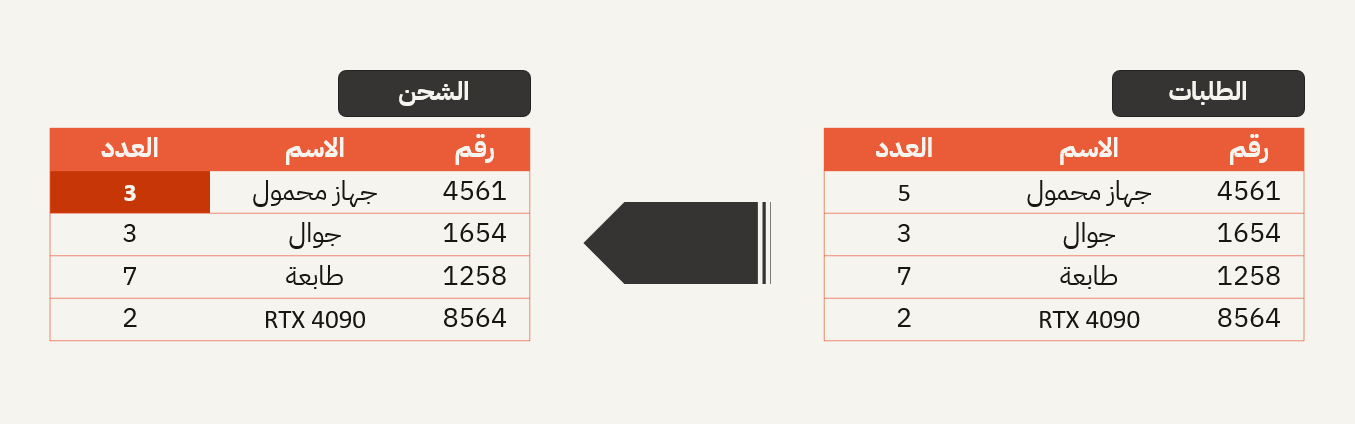
- اتساق البيانات بين مجالات الموضوع
ضمان الاتساق بين مجموعات البيانات في مجالات موضوع مختلفة. على سبيل المثال، تُظهر مجموعة بيانات طلبات العملاء طلبًا لخمسة أجهزة كمبيوتر محمولة، بينما تُظهر مجموعة بيانات المخزون ثلاثة أجهزة كمبيوتر محمولة فقط متاحة لنفس الطلب.
- اتساق بيانات المعاملات
يجب أن تنجح المعاملات فقط إذا نجحت جميع العمليات. إذا لم يتم تنفيذ المعاملة بشكل صحيح، فإنها تؤدي إلى عدم الاتساق. على سبيل المثال، يُظهر حساب مصرفي إيداعا بقيمة 500 ريال، لكن سجل المعاملات يشير إلى أن الإيداع لم تتم معالجته بالكامل، مما يؤدي إلى اختلاف في الرصيد.

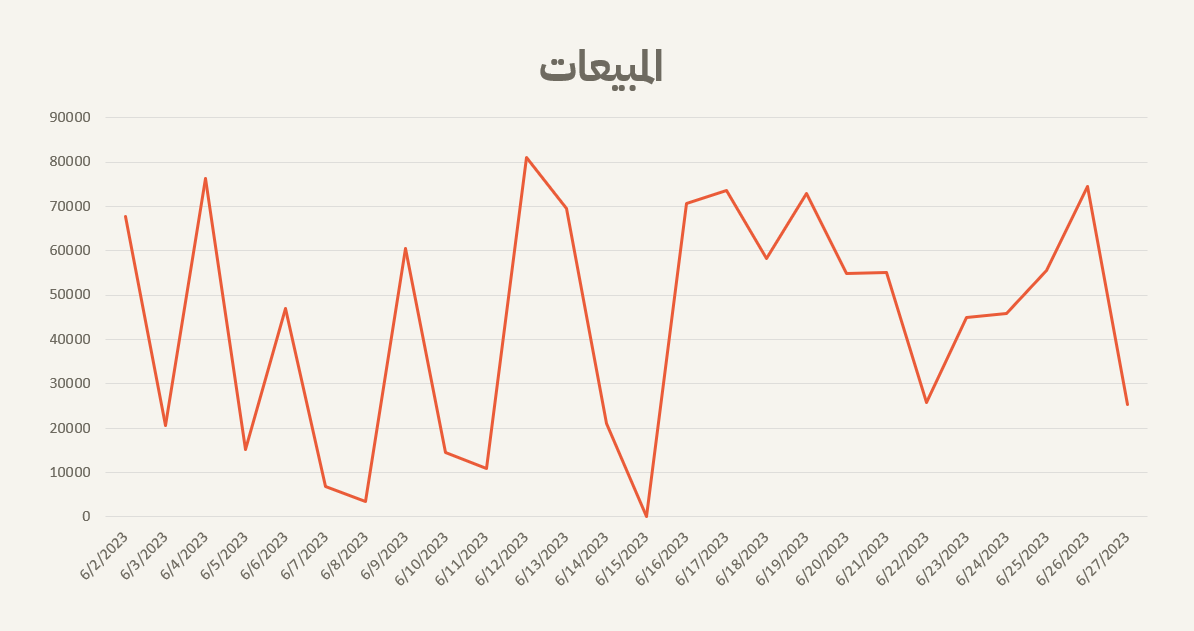
- اتساق البيانات بمرور الوقت
يجب أن تظل قيم البيانات وأحجامها متسقة بمرور الوقت مع اختلافات طفيفة ما لم يكن هناك تغيير كبير في الأعمال. على سبيل المثال، تُظهر بيانات المبيعات اليومية لشركة انخفاضًا مفاجئًا إلى صفر مبيعات في يوم معين، ويرجع ذلك على الأرجح إلى فشل في جمع البيانات بدلاً من أداء المبيعات الفعلي.
- الاتساق في تمثيل البيانات عبر الأنظمة
تخزين البيانات المرجعية بشكل متسق عبر مخازن بيانات متعددة. يمكن أن يحدث التمثيل غير المتسق عندما يتم تمثيل نفس المفهوم التجاري بشكل مختلف. على سبيل المثال، قد يتم إدراج فئة منتج على أنها “إلكترونيات” في نظام واحد و “سلع إلكترونية” في نظام آخر، مما يسبب ارتباكًا ومشاكل في تكامل البيانات. وتعتبر الموائمة أحد الحلول لمثل هذه المشاكل ولكن رصدها اذا كانت متغيره بشكل كبير يعتبر تحدي كبير جدًا
التفرد
يشير التفرد في جودة البيانات إلى ضرورة تسجيل الكيان أو الحدث مرة واحدة فقط في مجموعة البيانات. لا أحد يرغب في وجود بيانات مكررة لأنها قد تؤدي إلى العد المزدوج أو إنشاء تقارير خاطئة.
على سبيل المثال لا الحصر:
- تمثيل كيان واحد بهويتين مختلفتين
- تمثيل كيان واحد عدة مرات بنفس الهوية
أ. تمثيل نفس الكيان بهويات مختلفة:
هناك توقع عام بأن الكيان الفعلي الواحد يجب أن يُمثَّل مرة واحدة فقط. لنأخذ مثالاً على ذلك:
تم تسجيل طالب في قاعدة بيانات الجامعة مرتين:
- محمد أحمد العلي (الاسم الكامل)
- محمد العلي (اسم مختصر)
من يصل إلى هذه البيانات سيرتبك حول كيفية الإشارة إلى الطالب. أيضًا، قد يتم تخزين معلومات الطالب بشكل جزئي عبر السجلين. ستحسب الجامعة عدد الطلاب كاثنين بينما هناك طالب واحد فقط.
إذا قمت بفحص البيانات ببساطة، لا يمكنك تحديد ما إذا كان محمد أحمد علي ومحمد علي هما نفس الشخص لأن الأسماء مختلفة. ستحتاج إلى معلومات ثانوية ولكن فريدة عالميًا مثل البريد الإلكتروني أو رقم الهوية الوطنية لإزالة التكرار من هذه السجلات.
ب. تمثيل نفس الكيان عدة مرات بنفس الهوية:
في هذه الحالة، يكون معرف السجل متطابقًا تمامًا. هذه الحالة أسهل في الكشف لأنه يمكن مقارنة المفاتيح في مجموعة البيانات مع بعضها البعض للعثور على التكرارات.
مثال: تم تسجيل فاتورة مبيعات برقم 1001 مرتين في نظام المحاسبة:
- رقم الفاتورة: 1001، التاريخ: 2024/06/28، المبلغ: 500 ريال
- رقم الفاتورة: 1001، التاريخ: 2024/06/28، المبلغ: 500 ريال
هذا النوع من التكرار يمكن اكتشافه بسهولة عن طريق البحث عن أرقام الفواتير المتكررة في قاعدة البيانات. ومع ذلك، فإنه قد يؤدي إلى مشاكل خطيرة مثل المبالغة في تقدير المبيعات أو الأرباح إذا لم يتم اكتشافه وتصحيحه.
في كلتا الحالتين، يعد التفرد أمرًا بالغ الأهمية لضمان دقة البيانات وموثوقيتها، مما يساعد في اتخاذ قرارات أفضل وأكثر دقة بناءً على هذه البيانات.
التوقيت
يشير مصطلح توقيت البيانات إلى التأخير بين حدوث الواقعة وتوفر البيانات القابلة للاستخدام في النظام. قد ينتج هذا التأخير عن الوقت اللازم لالتقاط معلومات الحدث ومعالجتها وتخزينها، وهو أمر لا يحدث فورياً أبداً. يعد التوقيت بعداً حاسماً في جودة البيانات، حيث يمكن اعتبار البيانات الدقيقة ذات جودة رديئة إذا وصلت متأخرة جداً عن الغرض المقصود منها. على سبيل المثال وصول البيانات متأخرة للعمليات التجارية (مثلا نظام حجوزات مطعم وبحجز العميل اونلاين ولكن الموظفين لا ينظرون للنظام الا كل ساعتين مما يعطي انطباع سيئ لدى العميل) والتأخيرات الزمنية في الأنظمة الفورية (مثل التأخيرات في بيانات التنبؤ بالطقس التي تؤثر على قرارات ادارة الازمات والكوارث أو التأخيرات في مستشعرات السيارات ذاتية القيادة التي قد تسبب حوادث). في كلتا الحالتين، قد تكون البيانات نفسها صحيحة، لكن توفرها المتأخر يجعلها أقل قيمة أو حتى عديمة الفائدة للتطبيق المقصود.
الصلاحية
قياس صحة البيانات يحدد مدى دقة البيانات في عكس القيم أو الحسابات المتوقعة. ثلاثة جوانب رئيسية لصحة البيانات هي:
- صحة البيانات المستندة إلى القواعد
- صحة البيانات المستندة إلى النطاق (للقيم العددية والتاريخية)
- صحة البيانات المستندة إلى التسلسل
أ. صحة البيانات المستندة إلى القواعد أو الحسابات: تتحقق من مدى توافق البيانات مع القواعد الموضوعة، بغض النظر عن طريقة إدخالها. على سبيل المثال، في نظام إدارة المطاعم، يجب أن يكون المبلغ الإجمالي للفاتورة مساويًا لمجموع تكاليف العناصر الفردية بالإضافة إلى الضرائب. يمكن للنظام التحقق من ذلك بمقارنة الإجمالي المسجل مع المجموع المحسوب.
ب. صحة البيانات المستندة إلى النطاق: تضمن أن البيانات تقع ضمن نطاقات مقبولة محددة مسبقًا. تشمل الأمثلة:
- القيم العددية: في نظام السجلات الطبية، قد تعتبر درجة حرارة جسم الإنسان البالغ صحيحة فقط إذا كانت بين 95°F و 108°F (35°C و 42.2°C).
- التواريخ: في نظام طلبات التوظيف، يجب أن تؤدي تاريخ ميلاد المتقدم إلى عمر يتراوح عادةً بين 18 و 70 عامًا.
ج. صحة البيانات المستندة إلى التسلسل: تتحقق من وقوع الأحداث بترتيب منطقي. في منصة تعليمية، يجب أن لا يكون تاريخ إتمام الدورة للطالب قبل تاريخ تسجيله. وبالمثل، في أداة إدارة المشاريع، يجب أن لا يكون تاريخ بدء المهمة لاحقًا لتاريخ انتهائها.
اخيرا
في نهاية هذا الجزء، رأينا كيف أن عالم الذكاء الاصطناعي يتغير بشكل كبير. أصبحنا نركز أكثر على البيانات بدلاً من النماذج فقط. هذا التغيير مهم جداً.
تعلمنا عن أهمية جودة البيانات وكيف أن تحسينها يمكن أن يجعل أنظمة الذكاء الاصطناعي تعمل بشكل أفضل بكثير. عرفنا عن الدقة، والاكتمال، والاتساق، والتفرد، والتوقيت، والصلاحية في البيانات. كل هذه الأمور تساعدنا على بناء أنظمة ذكاء اصطناعي أقوى وأكثر موثوقية.
هذا التغيير ليس فقط في الطريقة التي نعمل بها، بل في طريقة تفكيرنا أيضاً. بدلاً من التركيز فقط على بناء النماذج، أصبحنا نفكر أكثر في كيفية جمع وتحسين البيانات التي تغذي هذه النماذج.
في مقالتنا القادمة ينتظرق الى عملية التوسيم للبيانات وكيف ممكن يكون جزء قليل من البيانات ذات جودة عالية في التوسيم ان تعطي نموذج بكفائة عالية.
المصادر
6 Dimensions to Measure Data Quality in Your Company | Pragmatic Institute
Meet the data quality dimensions – GOV.UK (www.gov.uk)
A Guide for Data Quality (DQ) and 6 Data Quality Dimensions (icedq.com)
Data-Centric Machine Learning with Python – <v1>






