

النماذج اللغوية الكبيرة (LLMs) تنتشر بسرعة داخل صناعة الذكاء الاصطناعي الإبداعي، آخذه كثيرًا من الإهتمام. لا تظهر الشركات اهتماماً فقط بل تنخرط لاستكشاف طرق دمج تكنولوجيا النماذج اللغوية الكبيرة LLMs في عملياتها. تم إجراء استثمارات مالية كبيرة في الآونة الأخيرة في أبحاث وتطوير النماذج اللغوية LLMs. هناك شغف بين قادة الصناعة وعشاق التكنولوجيا لتعزيز فهمهم للنماذج اللغوية LLMs. حتى تقوم بدمج هذه التقنية في عملك انت بحاجة الى فهم طرق عملها وتهيئتها وكيفية تجهيز البيانات.
ضمن دورة حياة النموذج اللغوي الكبير LLM، يشترك العديد من الخطوات الرئيسية، واليوم، سنتناول إحدى المراحل الأكثر أهمية – عملية الضبط الدقيق Fine-Tuning. هذه العملية تتطلب عدة امور منها Dataset ذات جودة عالية, فهم لكيفية ضبط Parameters للنموذج, ومع انتشار الكثير من النماذج المفتوحة المصدر فكل نموذج لديه Instruction الخاصة بضبطه!
ستكون أول خطوات الضبط Fine-Tuning هو تهيئة وتجهيز مجموعة البيانات, هذه الخطوة مهمة جدًا ويجب عليك اعطائها 80% من وقت بناء النموذج. تليها خطوات إيجاد الطريقة المُثلى للـParametrs حتى تصل الى اقصى دقة ممكنة. وتنتقل اخيرًا الى قياس دقة النموذج Evaluation.

مجموعة البيانات Dataset
مجموعة البيانات هي المحك لجودة اي نموذج في مجال الذكاء الاصطناعي, يتم الاستثمار فيها الكثير من الوقت لتنقيحها وتنظيفها وتجهيزها لمهام محددة. اذا كانت البيانات ذات جودة سيئة فلا تتوقع نتائج مبهرة. في مجال اللغات الطبيعية يختلف الوضع عن اي مجال يندرج تحت الذكاء الاصطناعي, هنا تحتاج الى قياسات مختلفة ومراجعة بشرية اذا دعت الحاجة لانها تهتمد على المعلومات الصحيحة والكتابة الصحيحة وخلافه.
في حقل الضبط لنماذج اللغات اللغوية الضخمة LLMs, هناك عدة انواع لمجموعة البيانات, هذه الأنواع المختلفة تكون لها طريقة تجهيز وجمع مُختلفة. سنقوم بإستعراض هذه الأنواع سويًا وسنقوم بإختيار نوع للبدء في تجربتنا في ضبط النموذج.
مبدئيًا هناك ثلاث أنواع لمجموعة البيانات:
- مجموعة البيانات التعليم: تحتوي هذه البيانات على تعليمات Instructions ومخرجات بناءًا على التعليمات المُعطاه Output, مثال سؤال وجواب على السؤال.
- الإكمال البحت: هذه البيانات الهدف منها توقع او تنبؤ الكلمة التالية مثل الإكمال التلقائي, هذه البيانات لاتصلح مثلًا لنموذج لغة خاص بالمحادثة لانه لم يدرب على التعليمات.
- مجموعات بيانات التفضيلات: هذا النوع من البيانات يستخدم التدريب المُعزز لعدة اجابات, يقدر يعطيك أكثر من جواب لنفس التساؤل ويساعد النموذج للإختيار افضل إجابة.
- أخرى : مثلا مجموعة بيانات لتصنيف النص مثلا ايجابي سلبي, مجموعة البيانات الخاصة بالأكواد البرمجية والمستخدمة مثلا في GitHub Copilot.
لا تقتصر انواع البيانات على ماتم ذكره سابقًا, فهذا المجال كل يوم يصدر شئ جديد او فكرة جديدة, متابعتك الدائمة مفتاح نجاحك.
في هدفنا الي بنحققه اليوم بنستخدم النوع الأول من مجموعة البيانات وخلنا نقول عنها Supervised Dataset, للأن التعليمات والإجابات معطاه سابقًا. هناك العديد من مجموعة البيانات يمكنك استخدامها من Huggingface أو اي موقع يفدم مجموعات بيانات جاهزة للإستخدام. يمكنك ايضًا انشاء مجموعة البيانات الخاصة بك او تعديل وتصفية المجموعات الموجودة سابقًا. في هذا التعديل سنقوم بإستخدام Huggingface.
🤗Hugginface
من أهم المصادر في مجال معالجة اللغات الطبيعية NLP، حيث تقدم مكتبة “Transformers” للنماذج المتقدمة, ,تحتوي على نماذج مُدربة مُسبقًا Pre-trained Models, ايضًا مجموعة كبيرة جدًا من مجموعات البيانات لمختلف المهمات.
للبد في ضبط النموذج اللغوي سنقوم بإستخدام Colab, لأنه يقوم بإعطاك GPU مجانًا للإستخدام وأيضًا يوفر خيارات الإشتراك اذا كنت بحاجة لـGPU أكثر قوة وبعض المميزات الأخرى.
تثبيت المكتبات
في مجال النماذج اللغوية وتحليل اللغات الطبيعية هناك العديد من المكتبات التي يمكن استخدامها لبدء العمل على عملية الضبط Fine-Tune, سنقوم باضافة المكتبات التالية:
- Transformes : توفر المحولات (Transformers) والعديد من الإضافات الأخرى
- SentenceTRansformer : توفر هذه المكتبة طريقة سهلة لحساب تمثيلات Vectors للجمل
والفقرات والصور. - faiss-gpu : هي مكتبة للبحث عن التشابه وتجميع Vectors. تحتوي على خوارزميات
تبحث في مجموعات من المتجهات Vectors من أي حجم، حتى تلك التي ربما لا تتناسب مع ذاكرة الـ (RAM). - datasets: يتيح لك الوصول الى جميع مجموعات البيانات الموجودة والمسموح الوصول لها في Huggingface
!pip install -q datasets transformers sentence_transformers faiss-gpu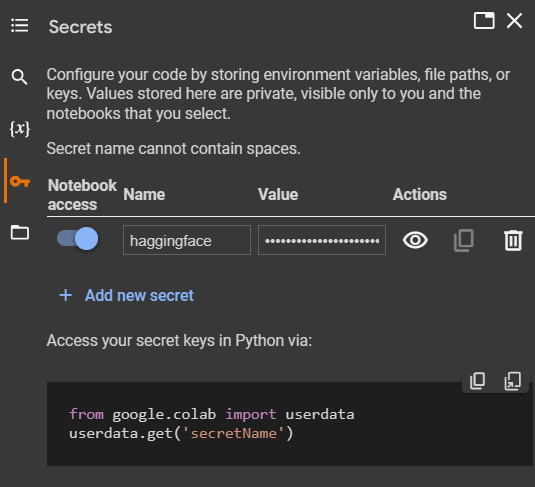
بحكم اننا نقوم بإستخدام Huggingface نحتاج الى Token حتى يسمح لنا بلإتصال الموقع وتحميل سواء Embedding او النماذج Models وايضَا مجموعات البيانات Dataset. يمكنك الحصول على Token من Huggingface من خلال قائمة الإعدادت ثم اختيار Access Token.
يقدم لك Colab بيئة لحفظ الأرقام الخاصة والمهمة مثل Token وخلافه حتى لو قمت بمشاركة Notebook مع اي شخص او على Github تكون بياناتك في مأمن من المشاركة.
الصورة التالية توضح لك طريقة إضافة Token داخل بيئة Colab, قمت بتسمية Name بـHugginface والقيمة هي Token الذي قمت بنسخة سابقًا.
الآن بعد إضافة Secrets Key نحتاج الى إضافتة في Notebook حتى يمكننا الإتصال بـHuggingface. سيكون هذا فقط بكتابة السطريين التاليين:
from google.colab import userdata
hf_token = userdata.get('haggingface')مجموعة البيانات:
سنقوم بتحميل مجموعة بيانات Dataset من Huggingface ونختار مجموعة بيانات sharegpt, هذه المجموعة تم انشائها عن طريق مستخدمين chatGPT, اذا سأل المستخدم سؤال للـchatGPT وكانت الإجابة صحيحة يقوم الشخص بمشاركة هذه الإجابة مع موقع خاص بحفظ هذه المحادثات, يمكنك الإطلاع عليها من هنا (رابط sharegpt).
يُقال ان Google Bard, استخدم بعض هذه المحادثات خلال تدريبهم لنموذجهم اللغوي الجديد, قام المطورين بإغلاق الوصول لبقية البيانات.
يحتوي الموقع على العديد من المحادثات بلغات مختلفة وأيضًا تنوع كبير في الأسئلة, لكن لغرض هذا الشرح سنقوم بإستخدام اللغة الإنجليزية فقط. يمكنك البحث عن الغة العربية فقط واستخدامها.
تحميل مجموعة البيانات
يُقدم Huggingface طريقة واضحة ومباشرة لتحميل البيانات من موقعهم, في الكود التالي سنقوم بتحميل البيانات.
from datasets import load_dataset
dataset = load_dataset('theblackcat102/sharegpt-english')تنتظر التحميل وبعد ذلك اذا حبينا نستعرض البيانات نقوم بتحويلها الى pandas, في الكود التالي توضح الطريقة.
dataset['train'].to_pandas()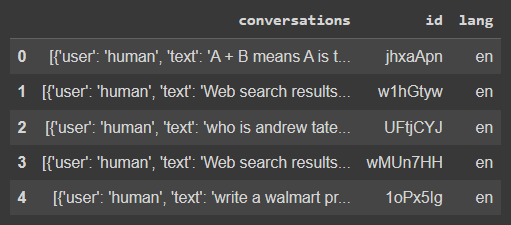
البيانات عبارة عن محادثات بين شخص وchatGPT, كل صف عبارة عن محادثة كاملة, وبعضها المستخدم طلب إكمال الرد, سنقوم بتصفيتها بحيث نأخذ فقط اول سؤال وأول رد.
human_data = []
gpt_data = []
for row in tqdm(dataset['train']):
current_instruction = {"human": "", "gpt": ""}
data = row['conversations']
current_instruction["human"] = data[0]["text"]
current_instruction["gpt"] = data[1]["text"]
human_data.append(current_instruction["human"])
gpt_data.append(current_instruction["gpt"])حفظنا سؤال المستخدم في قائمة وجواب GPT في قائمة منفصلة, بعد ذلك سنحولها الى pandas ونشوف كيف يكون شكلها.
df = pd.DataFrame({"human": human_data, "gpt": gpt_data})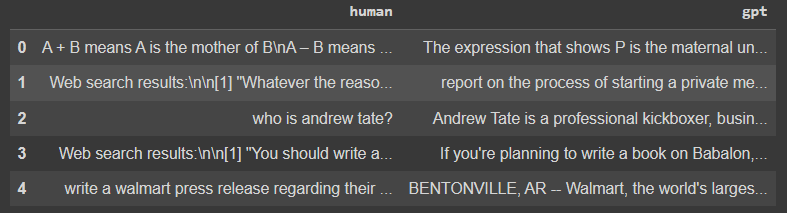
الآن البيانات اصبحت جاهزة. الان سنكمل تجهيز البيانات لعملية التعديل على النموذج المُدرب مُسبقًا.
Tokenize
سنستخدم مكتبة HuggingFace Transformers، وتحديداً AutoTokenizer، لتوكينة Tokenize النصوص في مجموعة البيانات. بدايةً نقوم باستيراد المكتبات اللازمة، بما في ذلك مكتبة Hugging Face Transformers (AutoTokenizer) ومكتبة Matplotlib لعرض البيانات ومكتبة Seaborn لتصوير البيانات.
تستخدم الدالة AutoTokenizer.from_pretrained لتحميل توكينايزر مدرب مسبقًا من نظام HuggingFace ModeHub. التوكينايزر ضروري لتحويل النص الخام إلى توكينات Tokens، التي تعتبر الوحدات الأساسية في معالجة اللغة. يقوم الكود بتوكينة نماذج النصوص من مجموعة البيانات (التي تسمى dataset). وبما أن مجموعة البيانات لدينا تحتوي على أزواج من الأمثلة، حيث يُمثل ‘human’ نص مكتوب بواسطة إنسان، و ‘gpt’ يُمثل نصًا تم إنشاؤه بواسطة نموذج GPT. بعد ان نقوم بتحويل النص الى Token سنتعرف ايضُا على عدد التوكن في كل رسالة.
from transformers import AutoTokenizer
from matplotlib import pyplot as plt
import seaborn as sns
tokenizer = AutoTokenizer.from_pretrained('mistralai/Mistral-7B-Instruct-v0.1')
instruction_token_counts = [len(tokenizer.tokenize(example['human'])) for example in dataset['train']]
output_token_counts = [len(tokenizer.tokenize(example['gpt'])) for example in dataset['train']]تلاحظ استخدمنا ‘mistralai/Mistral-7B-Instruct-v0.1 وهو النموذج المُدرب المستهدف تعديله.
تمثيل التوكنز
الآن سنقوم بعرض بعض الشارت لمعرفة وش اكثر توكن متكرر عندي وهل يوجد توكن اكبر من المطلوب حتى نقوم بتحديد اعلى length نقدر نتعامل معه.
سنستخدم Barchart لهذا الغرض من seaborn, سنقوم بتمثيل المُدخل من المستخدم وايضًا المُخرجات من GPT.
عدد التوكن المجموع بين Human و GPT
الصورة التالية توضح عدد التوكن لرسالة الشخص مضافُا اليه عدد التوكن للـGPT, هذا التصوير يعطينا كم عدد التوكن الأكثر تكرار,. هذا التصوير يساعدنا في تجنب الرسائل الطويلة لأن نماذج اللغة لها عدد محدد من Token التي تستقبلها كمدخلات.
Context Windows
هو عدد الـToken التي يستطيع نموذج LLM التعامل معها كمدخلات, فمثلُا نموذج GPT-3 يستقبل 2000 Token أما الاصدار GPT-4 يستطيع التعامل مع 32000 Token.
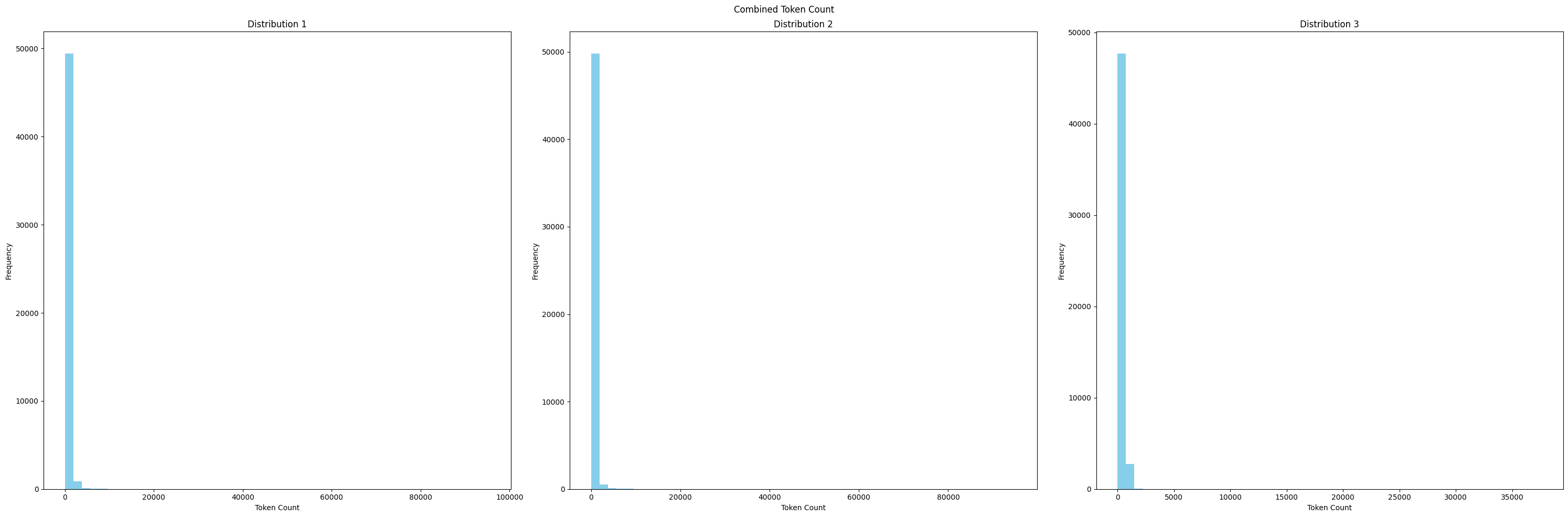
من الرسم البياني السابق تلاحظ ان هناك عدد كبير من الـTokens, التي لا يمكن التعامل معها في حالتنا اذا اردنا اعادة ضبط نموذج Mistral. الخطوة الجاية هي عملية فلترة لعدد الـTokens بحيث لا تتجاوز الـContext-window.
تحديد عدد Tokens:
الآن سنقوم بعملية فلترة لعدد Tokens الى 4096, هذا لا يعني ان النموذج لا يستطيع التعامل مع Context-window أكبر من هذا الرقم, لكن لغرض هذا الشرح سنكتفي بعدد 2048.
valid_indices = [i for i, count in enumerate(combine_token_counts) if count <= 4096]قمنا بعملية الـفلترة بحيث يقوم فقط بالحفاظ على عدد الـToken اقل من او يساوي 4096, بعد ذلك ينقوم بتنقح مجموعة البيانات حتى تتوافق مع المطلوب. هذا يبكون بإستخدام سطر الكود القادم, فعنصر Dataset من HuggingFace يقدم لنا طريقة سهلة لإختيار البيانات المطلوبة.
dataset['train'] = dataset['train'].select(valid_indices)نتيجة الكود السابق هو ماستلاحظة في الرسم البياني التالي بحيث ان عدد Tokens لن يتجاوز 4096, وهذا هو الهدف المطلوب.
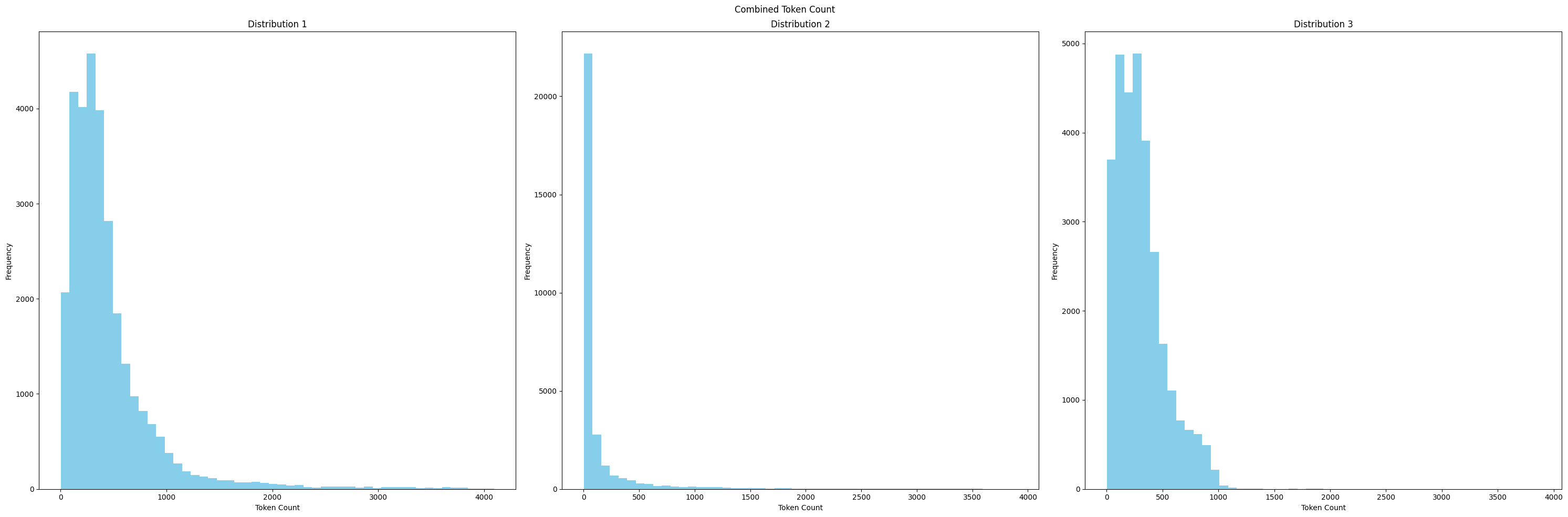
الآن بعد ان قمنا باختيار عدد Token المطلوب سنقوم بالتحقق هل لدينا بيانات او مدخلات متشابهة, لا اقصد هنا متشابهة 100% كما نفعل في Drop Duplicate, وانما تقريبًا متشابهة!
حذف التكرار
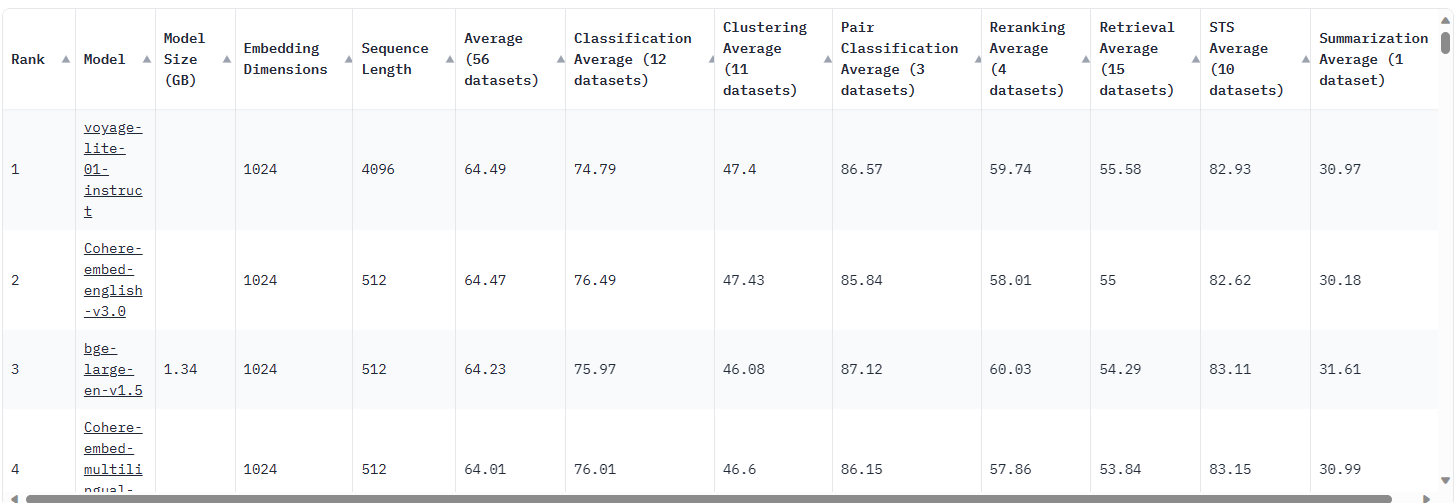
سقوم بحذف البيانات القريبة من التكرار, سنتخدم Embedding لتحويل جميع البيانات لدينا, هناك العديد من النماذج للـEmbedding يمكن الإختيار من بينها, لكن HuggingFace قدم لمت صفحة خاصة بجميع خيارات Embedding وكيف ادائها وبمكن اختيار مايتناسب مع طريقة عملك. يمكنك زيارة هذا الموقع والإطلاع عليها.
MTEB Leaderboard – a Hugging Face Space by mteb
الآن سنقوم بكتابة هذا الكود
from sentence_transformers import SentenceTransformer
import faiss
from datasets import Dataset, DatasetDict
from tqdm.autonotebook import tqdm
import numpy as np
def deduplicate_dataset(dataset: Dataset, model: str, threshold: float):
sentence_model = SentenceTransformer(model)
outputs = [example['gpt'] for example in dataset['train']]
print('Text to embedding')
embeddings = sentence_model.encode(outputs, show_progress_bar=True)
dimension = embeddings.shape[1]
index = faiss.IndexFlatIP(dimension)
normalized_embeddings = embeddings / np.linalg.norm(embeddings, axis=1, keepdims=True)
index.add(normalized_embeddings)
print('Filtering out')
D, I = index.search(normalized_embeddings, k=2)
to_keep = [i for i in tqdm(range(len(embeddings)), desc='Filtering') if D[i, 1] < threshold]
dataset = dataset['train'].select(to_keep)
return DatasetDict({'train': dataset})
deduped_dataset = deduplicate_dataset(dataset, 'thenlper/gte-large', 0.95)يمكن شرح الكود السابق في ثلاث نقاط رئيسية:
1. تهيئة وتعريف الدالة:
- الدالة تأحذ ثلاث مدخلات, مجموعة البيانات, اسم النموذح الذي يقوم باستخدامة مع SentenceTransformer و threshold الذي يوضح الى اي درجة النص متشابهه, لدينا هنا 0.95 وهذا بالطبع يختلف باختلاف النموذج المستخدم.
- سنأخذ اجابات GPT كمدخلات للـSentenceTransformer
- سنقوم بحساب الـembeddings لكل الصفوف في مجموعة البيانات.
2. الفهرسة والفلترة باستحدام Faiss:
- Faiss تقدم العديد من الطرق للفهرسة, في هذا الشرح استخدمنا IndexFlatIP, يعطي سرعة أكبر وجودة أعلى في البحث.
- قمنا بعمل تسوية “normalized” للـ،Embeding قبل إضافتها الى Faiss.
- بعدها قمنا بعملية الفلترة باستخدام threshold المحدد سابقًا.
3. إعادة مجموعة البيانات
بعد القيام بهذه العملية والبحث عن المتشابهات سنقوم فقط بالحفاظ على البيانات غير المتماثلة واستخدامها في عملية ضبط النموذج,بعد قيامنا بهذه الخطوة تخلصنا من قرابة 20K صف متشابة واصبح لدينا فقط 30K عينة للقيام بعملية الضبط.
قالب الدردشة
مع ظهور نماذج اللغات الضخمة ظهرت العديد من القوالب والتعليمات لضبط هذه النماذج, تقريبًا كل نموذج لديه الطريقة الخاصة لضبط التعليمات, سنتعرف اولاُ على التعليمات الشائعة لقوالب الدردشة بعد ذلك سنقوم بتعديل مجموعة البيانات للتوافق مع Mistral وتعليماته. لأن اختلاف طريقة التعليمات التي تم بنائه بها او ماستقوم انت باستخدامه يؤثر بشكل كبير على اداء النموذج.
ابسط شكل لقالب الدرشة هو التالي:
[
{"role": "user", "content": "Hi there!"},
{"role": "assistant", "content": "Nice to meet you!"}
]يجب تحويل هذا التسلسل من الرسائل إلى سلسلة نصية قبل أن يتم ترميزها “tokenized” واستخدامها كمدخل للنموذج. لكن المشكلة هي أن هناك طرقًا عديدة للقيام بهذا التحويل! يمكنك، على سبيل المثال، تحويل قائمة الرسائل إلى تنسيق “مراسلة فورية”:
User: Hey there!
Bot: Nice to meet you!أو يمكنك إضافة رموز خاصة للإشارة إلى الأدوار:
[USER] Hey there! [/USER]
[ASST] Nice to meet you! [/ASST]أو يمكنك إضافة رموز مميزة للإشارة إلى الحدود بين الرسائل، ولكن قم بإدراج معلومات الدور كسلسلة:
<|im_start|>user
Hey there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>وهناك العديد من الطرق للقيام بذلك, لكن في حالتنا سنقوم باستخدام هذه الطريقة التالية:
text = "<s>[INST] What is your favourite condiment? [/INST]"
"Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s> "
"[INST] Do you have mayonnaise recipes? [/INST]"الرائع هو ان HuggingFace تقدم طريقة سهلة لتنفيذ هذه التعليمات على مجموعة البيانات باسهل الطرق باستخدام apply_chat_template كما في الكود التالي:
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])لكن في الكود الخاص بنا سيكون بهذا الشكل:
def chatml_format(example):
message = {"role": "user", "content": example['human']}
if len(example['gpt']) > 0:
message_2 = {"role": "assistant", "content": example['gpt']}
else:
system = ""
system = tokenizer.apply_chat_template([message,message_2], tokenize=False,add_generation_prompt=True)
return {
"msg": system,
}ستكون النتائج بهذا الشكل
<s>[INST] Web search results:nn[1] "You shou...الآن اصبح كل شئ جاهز بالنسبة لمجموعة البيانات تبقى فقط حفظها
حفظ ونشر مجموعة البيانات
الآن بعد كل هذا التعديل والمعالجة تحتاج الى حفظ مجموعة البيانات حتى لاتضظر الى اعادة تشغيل كل هذه الخطوات, يمكنك حفظها على جهازك او نشرها على HuggingFace.
w_hf_token = userdata.get('w_hf')
dataset.push_to_hub('share-gpt', token=w_hf_token,private=True)هذه ابسط طريقة لنشر مجموعة البيانات على Huggingface, تأكد ان Access Token خاص بالكتابة وليس القراءة فقط.
الخاتمة
في هذا الدرس، تعلمنا كيفية تحضير مجموعة بيانات لضبط نموذج اللغة الضخمة. لقد غطينا الخطوات الأساسية التالية:
- تحميل مجموعة البيانات من HuggingFace أو إنشاء مجموعة بيانات خاصة بك.
- تنظيف البيانات وإزالة التكرارات.
- تحويل البيانات إلى تنسيق قابل للاستخدام من قبل النموذج.
في المثال الخاص بنا، استخدمنا مجموعة بيانات sharegpt، والتي تحتوي على محادثات بين مستخدمين وchatGPT. قمنا بتصفية البيانات لإزالة المحادثات الطويلة جدًا والمتكررة. ثم قمنا بتحويل البيانات إلى تنسيق يتوافق مع تعليمات Mistral.
بمجرد إعداد مجموعة البيانات الخاصة بك، يمكنك البدء في ضبط النموذج. في الشرح التالي، سنتعلم كيفية ضبط نموذج اللغة الضخمة باستخدام HuggingFace Transformers.
فيما يلي بعض النصائح الإضافية لإعداد مجموعة بيانات لضبط نموذج اللغة الضخمة:- تأكد من أن مجموعة البيانات الخاصة بك كبيرة بما يكفي لتدريب النموذج. بشكل عام، ستحتاج إلى مجموعة بيانات تحتوي على عشرات الآلاف أو حتى مئات الآلاف من الأمثلة.
- تأكد من أن مجموعة البيانات الخاصة بك متنوعة. يجب أن تغطي مجموعة البيانات مجموعة واسعة من الموضوعات والمواقف.
- تأكد من أن مجموعة البيانات الخاصة بك دقيقة. يجب أن تكون جميع الأمثلة في مجموعة البيانات صحيحة وقابلة للتطبيق.
باتباع هذه النصائح، يمكنك إنشاء مجموعة بيانات قوية ستساعدك على تدريب نموذج لغة ضخمة عالي الأداء.






