

لقد غيَّرت نماذج “Object Detection” التقليدية كيفية رؤية الحواسيب للعالم. تم توظيفها في العديد من المجالات بدءا من السيارات ذاتية القيادة إلى تصنيف المنتجات بشكل ألي. ومع ذلك، تعتمد هذه الأنظمة في الغالب على افتراض عالم مغلق – فهي لا تستطيع كشف إلا ما تم تدريبها عليه بشكل صريح. تخيل محاولة بناء نظام يمكنه اكتشاف كل شئ “Object” ممكن! ستكون البيانات التدريبية المطلوبة هائلة.
بعد ظهور نماذج اللغات الضخمة LLM استطاع الباحثون من دمجها مع نماذج Object detection باستخدام Open-vocabulary object detection (OVD). يسمح هذا للنماذج بالكشف عن الكائنات Object Detection بناءً على الوصف النصي حتى لو لم يتم تضمينها في مجموعة بيانات التدريب. تقدم هذه التقنيات هياكل تحويلية معقدة قائمة على المحولات Transformers التي وبلا شك مكلفة حسابيًا، مما قد يعوق استخدامها في التطبيقات في الوقت الفعلي Real-Time.
واحد من النماذج الشهيرة التي تستخدم هذه الطريقة هو “CLIP“، حيث يتيح للنموذج كشف وتصنيف الكائنات استنادًا إلى الوصف النصي المقدم له، مما يجعله أكثر مرونة في التعامل مع مجموعة متنوعة من الكائنات دون الحاجة إلى بيانات تدريبية محددة مسبقاً لكل كائن. ومع ذلك، يتطلب تنفيذ هذا النوع من النماذج موارد حسابية كبيرة بسبب تعقيد الهياكل واستخدام المحولات Transformers، مما قد يقلل من قدرتها على العمل بكفاءة في الوقت الفعلي، خاصة في الأنظمة التي تتطلب استجابة سريعة.

تقنية Zero-Shot Object Detection تستخدم للكشف عن Objects في الصور دون الحاجة إلى تدريب مسبق على تلك Objects. يتم تدريب النموذج على مجموعة متنوعة من الكائنات، ثم يُعطى وصف مفصل للكائنات التي لم يتم تدريبه عليها، ويستخدم هذا الوصف للكشف عن تلك الكائنات في الصور.
Zero-Shot Object Detection
YOLO-World
ظهرت نهاية شهر يناير ورقة بحثية جديدة بعنوان “YOLO-World: Real-Time Open-Vocabulary Object Detection” تطرح التحدي في هذا المجال. تهدف YOLO-World إلى جمع سرعة وفعالية YOLO (You Only Look Once) مع قوة الكشف بمفردات مفتوحة Open-Vocabulary . لكن كيف حققوا ذلك؟
في البداية سنقوم باستعراض مقارنة بين YOLO-World والطرق التقليدية للكشف عن الكائنات و الكشف عن الكائنات ذات المفردات المفتوحة, قام الباحثون باضافة هذه الصورة في الورقة لتوضيح بعض المفاهيم.
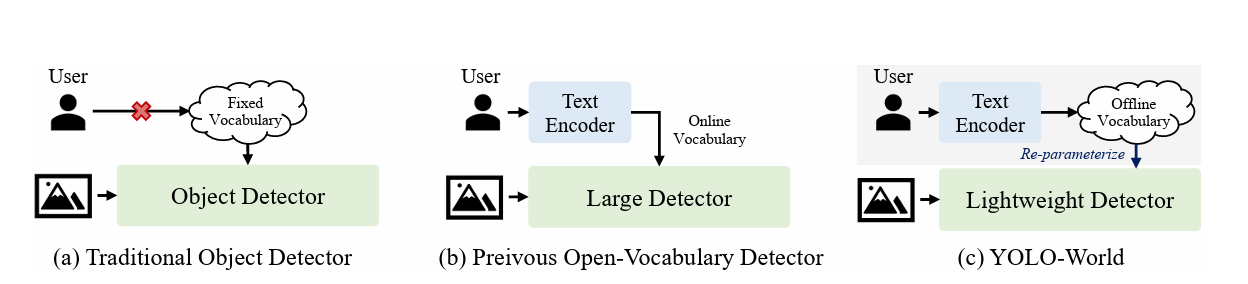
أ) Traditional Object Detector : محدودة بمفردات ثابتة “Classes” محددة مسبقًا أثناء التدريب، مثل 80 فئة في مجموعة البيانات COCO. هذا يحد من قدرتها على التعامل مع مشاهد مفتوحة “لم يتدرب عليها”.
ب) Previous Open-Vocabulary Detectors: تميل إلى استخدام كواشف ضخمة وثقيلة لتغطية open-vocabulary، بالإضافة إلى ترميز النصوص والصور معًا كمدخلات، مما يجعلها بطيئة للتطبيقات العملية.
Open-Vocabulary Detection يهدف إلى التعميم فوق عدد محدود من الفئات الأساسية الموسومة خلال مرحلة التدريب. الهدف هو الكشف عن فئات جديدة محددة بمفردات غير محدودة (مفتوحة) خلال مرحلة الاستدلال. دعنا نأخذ مثالًا لتوضيح مفهوم Open-Vocabulary Detection:
لنفترض أنك تدرب نموذجًا للكشف عن الكائنات على مجموعة بيانات تحتوي على فئات مثل السيارات، والقطط، والكراسي. في هذه الحالة، سيكون النموذج قادرًا على الكشف عن هذه الفئات الثلاث فقط في الصور الجديدة.
الآن، خذ في الاعتبار أنك تريد استخدام هذا النموذج للكشف عن كائنات في صورة جديدة تحتوي على كائنات لم يتم تدريب النموذج عليها، مثل طائرة ورقية والبرتقال. النماذج التقليدية ستفشل في الكشف عن هذه الكائنات الجديدة.
هنا يأتي دور تقنية Open-Vocabulary Detection. بدلاً من الاقتصار على الفئات التي تم التدريب عليها، تستطيع هذه النماذج الكشف عن الكائنات الجديدة غير المعروفة مثل الطائرة الورقية والبرتقال بناءً على خصائصها المرئية.
قد تقوم بتزويد النموذج بكلمات “طائرة ورقية” و”برتقالة” كدخل نصي إضافي للمساعدة في تصنيفها. أو قد يستخدم النموذج معرفته السابقة عن أشكال وألوان الأشياء لتحديد ما هي هذه الكائنات الجديدة.
بهذه الطريقة، لا يقتصر النموذج على فئات محددة مسبقًا، بل يمكنه التعامل مع Open-Vocabulary ومتغيرة من الكائنات في العالم الحقيقي دون الحاجة لإعادة التدريب من الصفر على كل فئة جديدة.
Open-Vocabulary Detection
ج) YOLO-World: يُظهر أداءً قويًا Open-Vocabulary باستخدام كواشف خفيفة الوزن مثل YOLO، وهو ما يعد مهمًا للتطبيقات العملية. بدلاً من استخدام مفردات متزامنة، يقدم نهج “prompt-then-detect“، حيث يولد المستخدم سلسلة من prompts حسب الحاجة، ويتم ترميزها كمفردات مُخزّنة مسبقًا. ثم يتم إعادة ضبط هذه المفردات كأوزان للنموذج بهدف التشغيل والتسريع.
بشكل عام، يسمح هذا النهج بالكشف عن Open-Vocabulary Detection بشكل فعال وسريع، دون الحاجة لنماذج ضخمة أو ترميز متزامن للنص والصورة.
بُنية النموذج
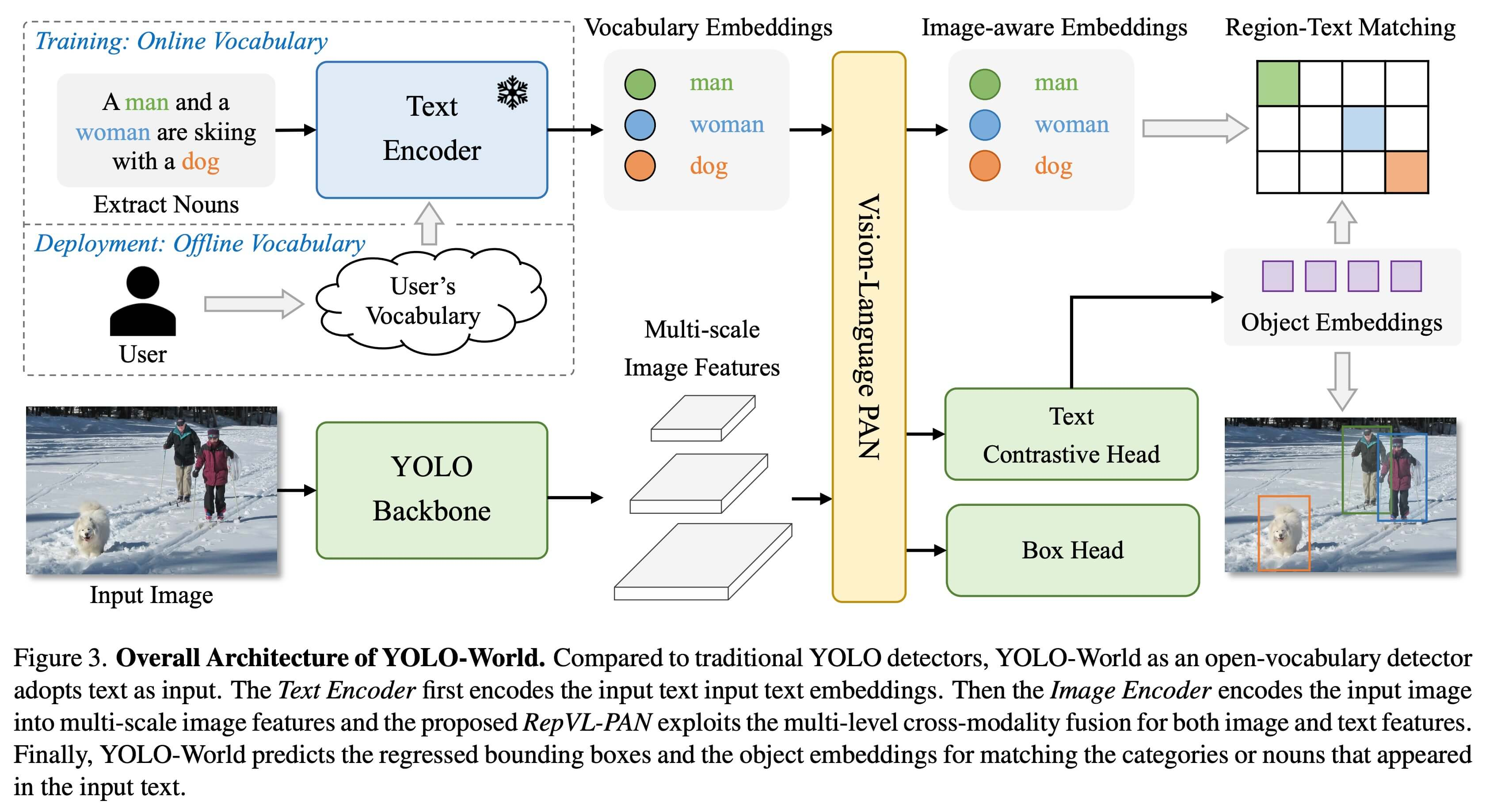
YOLO Base: هو العقل الأساسي. يستخدم نسخة خاصة من YOLOv8 التي تجيد الكشف عن الكائنات الشائعة والمعروفة. هذا الجزء يحلل الصورة، ويبحث عن الأشكال والألوان والكائنات المحتملة.
CLIP: هو المساعد الذكي الذي يفهم الكلمات! يمكنك إعطاؤه قائمة بالأشياء التي تريد البحث عنها مثل “شخص يرتدي قبعة” أو “قطة مخططة”. يفهم CLIP هذه الكلمات ويساعد YOLO-World في البحث عنها في الصورة.
RepVL-PAN: هنا مربط الفرس! يعمل كالجسر الذي يربط بين معلومات الصورة من العقل الأساسي ووصف الكلمات من CLIP. يقوم بمزج المعلومات المرئية مع الكلمات بعناية، لكي يحصل YOLO-World على الصورة الكاملة لاتخاذ قراراته.
هذا التفاعل بين الأجزاء المختلفة هو ما يمكن YOLO-World من الكشف عن أي كائن باستخدام Open-Vocabulary، سواء تم تدريبه عليها مسبقًا أم لا.
السرعة والدقة
هذا جدول يقارن أداء YOLO-World مع عدد من الطرق الأخرى للكشف عن الكائنات ذات المفردات المفتوحة (Open-Vocabulary Object Detection) على مجموعة البيانات LVIS.
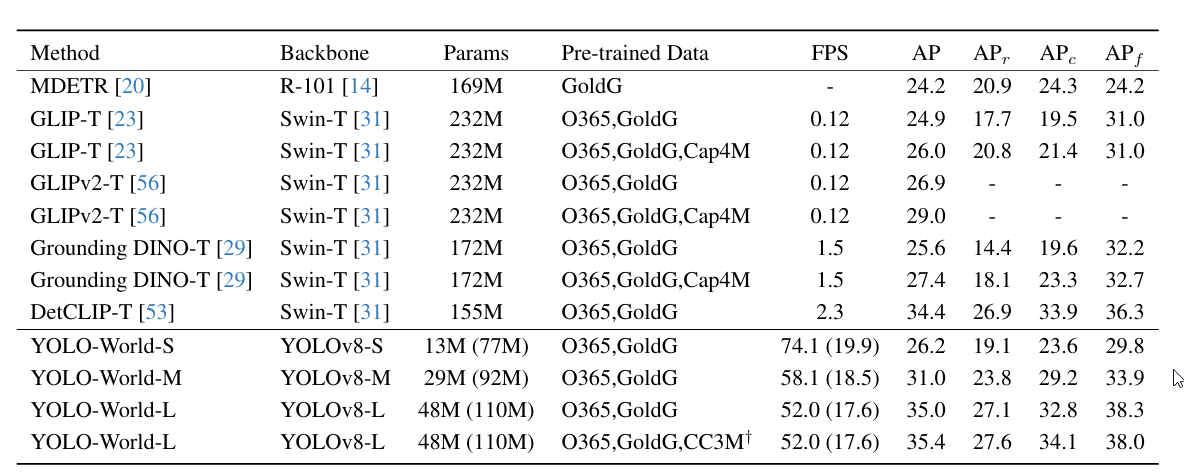
الجدول يعرض العديد من المقاييس لتقييم الأداء مثل:
- FPS: معدل الإطارات في الثانية لقياس السرعة
- AP: متوسط الدقة (Average Precision) الإجمالي
- APr, APc, APf: متوسط الدقة لفئات مختلفة (غير محددة، منسقة، جماعية)
كما يوضح الجدول تفاصيل النماذج المستخدمة مثل عمق الشبكة العصبية (backbone)، وعدد البارامترات، ومجموعات البيانات المستخدمة للتدريب المسبق.
النقاط الرئيسية التي يمكن استخلاصها:
- تظهر نماذج YOLO-World أداءً قويًا في الكشف عن المفردات المفتوحة Open-Vocabulary، خاصة الإصدارات الكبيرة مثل L، حيث حققت 35.0 في AP.
- تتفوق YOLO-World على العديد من الطرق الأخرى مثل MDETR و GLIP في معدل الإطارات في الثانية، مما يجعلها أسرع بكثير للاستخدام العملي.
بشكل عام، تُظهر هذه النتائج أن YOLO-World تقدم حلاً فعالاً وسريعًا للكشف عن الكائنات ذات المفردات المفتوحة مقارنةً بالطرق الأخرى.
الرسوم التوضيحية
يقدم المؤلفون رسومات توضيحية للـ YOLO-World-L المدرب مسبقًا في ثلاثة إعدادات:
(أ) يستخدم المؤلف LVIS للاستدلال zero-shot.
(ب) يدخل المؤلف custom prompt بفئات fine-grained وسمات attributes،
(ج) يشير إلى الكشف detection. تظهر هذه الرسومات التوضيحية أيضًا أن YOLO-World لديه قدرة تعميم generalization قوية في open-set، مصحوبة بالقدرة على الإشارة إليه.
الاستدلال zero-shot على LVIS. توضح الشكل 5 نتائج الرسوم التوضيحية visualization المُنشأة بناءً على فئة LVIS class، والتي تم إنشاؤها بطريقة zero-shot بواسطة YOLO-World-L المدرب مسبقًا. يُظهر YOLO-World المدرب مسبقًا قدرة zero-shot قوية ويستطيع اكتشاف أكبر عدد ممكن من الكائنات objects في الصورة.

في الشكل 6، يستكشف المؤلفون قدرة أداء اكتشاف YOLO-World بفئات categories محددة من قبل المؤلفين. تظهر نتائج الرسوم التوضيحية أن YOLO-World-L المدرب مسبقًا لديه أيضًا القدرات التالية:
(1) اكتشاف دقيق fine-grained detection (أي اكتشاف أجزاء من كائن object)
(2) تصنيف دقيق fine-grained classification (أي التمييز بين كائنات objects من فئات فرعية subcategories مختلفة).

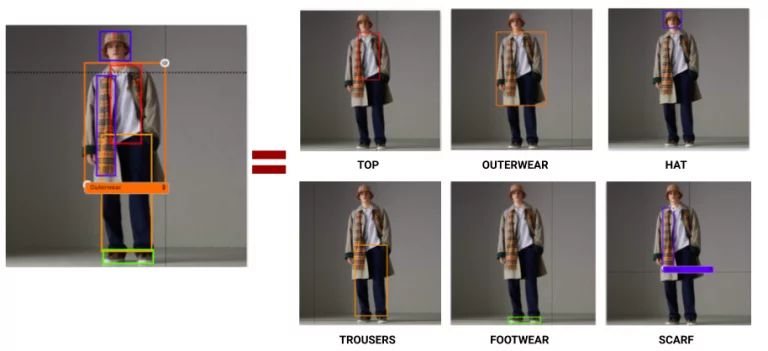
في الشكل 7، يستخدم الباحثون عدداً من العبارات الاسمية الوصفية (التمييزية) كمدخلات، مثل “الأشخاص الواقفون”، لاستكشاف ما إذا كان النموذج قادراً على تحديد المناطق أو الأهداف في الصورة التي تتطابق مع المدخلات المعطاة. تظهر عمليات المعاينة هذه العبارات ومربعات الاحتواء الخاصة بها، مما يدل على قدرة YOLO-World المدرب مسبقًا على الإشارة إليه أو تحديد موقعه. يمكن إرجاع هذه القدرة إلى استراتيجية التدريب المسبق المقترحة من قبل الباحثين لبيانات التدريب كبيرة النطاق.

يمكنك تجربة الـYOLO-World من هنا
YOLO World – a Hugging Face Space by stevengrove
الخاتمة
في الختام، يقدم YOLO-World حلاً واعداً للكشف عن الكائنات ذات المفردات المفتوحة Open-Vocabulary Object Detection بشكل فعال وسريع. من خلال الجمع بين قوة YOLO للكشف السريع وقدرات CLIP على فهم اللغة، يوفر نموذج YOLO-World أداءً قوياً في اكتشاف الكائنات حتى لو لم يتم تدريبه عليها مسبقًا.
تظهر النتائج التجريبية أن YOLO-World يتفوق على العديد من الطرق الأخرى في السرعة والدقة معاً، مما يجعله خياراً مثالياً للتطبيقات العملية التي تتطلب استجابة في الوقت الفعلي. علاوة على ذلك، تُظهر الرسوم التوضيحية قدرات قوية في الكشف الدقيق والتصنيف والإشارة إلى الكائنات.
بشكل عام، يمثل YOLO-World خطوة كبيرة نحو تحقيق الكشف عن الكائنات ذات المفردات المفتوحة لمجموعة واسعة النطاق من الكائنات في العالم الحقيقي. مع استمرار التقدم في هذا المجال، قد نشهد قريباً نماذج أكثر قوة وفعالية في اكتشاف وفهم العالم من حولنا.
المصادر
[2401.17270] YOLO-World: Real-Time Open-Vocabulary Object Detection (arxiv.org)
YOLO-World: A Breakthrough in Real-Time Open-Vocabulary Object Detection | by Mohsen Nabil | Feb, 2024 | Medium
YOLO-World: Real-Time, Zero-Shot Object Detection (roboflow.com)
AILab-CVC/YOLO-World at blog.roboflow.com (github.com)






