

الشبكات العصبية الإلتفافية CNN المبنية على المنطقة Region, والمعروفة بإسم R-CNN, قام Girshick وفريقة بتطوير ونشر ورقة علمية عن R-CNN عام 2014 من جامعة Berkeley. الورقة العلمية قدمت مفهوم جديد للـObject Detection مع اداء ودقة عالية وايضا قامت بحل مشكلات اكتشاف الكائنات Object Detection في الصورة من خلال انشاء المربعات المحيطة بالكائنات bounding boxes.
كان لهذه الورقة تأثير في مجال CNN وتم نشر العديد من النماذج التي اتخذت من R-CNN كأساس او مٌنطلق لها، بما في ذلك Fast R-CNN، وFaster R-CNN، وMask R-CNN،على التوالي, حيث يعتمد كل منها على قدرات سابقتها. لفهم الفروق الدقيقة في متغيرات R-CNN هذه، من الضروري إنشاء أساس وفهم متين في بنية R-CNN الأصلية.
في هذه المقالة سنقوم بأخذ نظؤة دقيقة على R-CNN ثم بعد ذلك سنعطي لمحات والاختلاف بينها وبين سابقاتها. سيكون هناك بعض الأكواد البرمجية لشرح بعض المفاهيم البسيطة وأيضًا تطبيق لما فهمناه.
ماهو R-CNN
مثل ماذكرنا سابقا, R-CNN نوع من انواع CNN والتي تعتمد في عملها على Region, تعتبر من أنواع Object Detection والي قدمت مفهوم جديد لحل بعض مهام الرؤية بالحاسب. فمن الواضح ان المميز هنا هو الـRegion وطريقتة. لكن خلنا نفهم قبل كيف Object Detection كان يعمل التمرير على الصورة. فمثلا في الصورة التالية بنوضح مفهوم الـتمرير بشكل مصور كمدخل للـRegion

مثلا لو افترضنا اني مهتم في هذه الصورة هو السيارات والشاة على جانب الطريق فستلاحظ ان التمرير يسوي تصنيف Classification لأماكن لا يوجد فيها كائن Object فيكون هذا اصلا شئ مكلف للموارد ومضيعة للوقت. فجت فكرة للباحثين ليش مابكون فيه طريقة اني بس “اشغل” التصنيف على الأماكن الي اتوقع ان فيها Object فحت هذي الفكرة والمسمى الي هو Region.
كيف تعمل هذه الخوارزمية او الفكرة
تتمحور فكرة R-CNN على ثلاث اشياء من خلال تطبيقهم لها
- نبحث عن Region يحتوي على كائن Object. والي اطلق عليه الباخثين region proposals.
- استخدم CNN لإستخراج Features من region proposals.
- تصنيف الكائنات Objects باستخدام الميزات Features المستخرجة.
المنطقة المقترحة Region Proposal
فلو نأخذ اول خطوة وهي region proposals فالفكرة تقوم باستخدام Segmentation Algorithm “التقسيم”. او باستخدام Edge Boxes وغيرها, طبعُا في هذه الخطورة يتم العديد من عمليات الـitrate حتى يكون لدينا العديد من المناطق المرشح ان يكون فيها Objects كائنات
فعلى سبيل المثال خلال هذه العمليات يتم دمج العديد من المناطق مع بعذهل غلى حسب الشكل او اللون كما ستلاحظ في الصورة التالية.

مثال من الورقة العلمية Selective Search من هنا Selective Search Explained | Papers With Code
الميزات Features المستخرجة.
بعد عملية Region Proposal يكون لدينا تقريبًا 2000 منطقة تم انشائها في غضون ثواني, بعد ذلك يتم استخراج هذه المناطق واعادة تحجيمها لتتناسب مع نماذج CNN الأخرى, لأن مثل ناذكرنا سابقُا بدل مامرر السلايد على كل الصزرة لا! اول شئ استخرج المناطق المحتمل يكون فيها كائن Object وهذه المناطق لنعتبرها اصبحت صور منفصلة يمكمن تمريرها الى اي نموذج CNN. عندما ذكرنا اعادة التحجيم فجميع المناطق المقترحة لاتحمل نفس الأبعاد التي من الممكن تكون قابلة لمعالجة من CNN فسنحتاج الى هذه الحطوة. ايضُا يتم اضافة 16 بيكسل حول المنطقة المرشحة لمحاولة أخذ اكبر قدر من الكائن Object. كما ذكر الباحثين
بغض النظر عن حجم المنطقة المرشحة او تناسب الأبعاد سيتم ضغط او ضبط ابعاد الصورة داحل إطار مع اعطاء ازاحة 16 بيكسل.
بعد ذلك يتم تغذية الصورة الى CNN حتى نقوم بعمليات التصنيف

من خلال الكلام السابق تلاحظ وكأن العملية عبارة عن مسار Pipeline تقوم فيه بالعديد من الخطوات حتى تصل الى النتيجة النهائية. الآن بعد استخراج الميزات سنفوم باستخدم Deep Neural Network عميقة مثل VGG، أو AlexNet، أو ResNet. اختار مؤلفو الورقة AlexNet، لذا لحالتنا سنستخدم أيضًا معمارية او نموذج AlexNet. من المهم أن نلاحظ أن AlexNet تم تدريبها أصلاً لتصنيف الصور Classfication بدلاً من الكشف عن الكائنات Object Detection. لتكييفها مع R-CNN، قام الباحثون بضبط “Fine-Tune” معمارية AlexNet.” هذا هو الفكرة خلف R-CNN ببساطة.
لكن مع جمال هذه الفكرة كانت تستغرق الكثير من الوقت وبطيئة واتت بعدها نماذج كل نموذج يحاول يصلح عيوب ماقبله, وكانت البداية من Fast R-CNN
Fast R-CNN
من عيوب R-CNN انها تحتاج تمرير 2000 صورة “ميزة” للشبكة العصبية CNN كل مرة او في كل صورة, وايضا كل صورة تحتوي على 2000 منطقة وهذا كله يستغرق ولايمكن مشاركة العمليات بين المدخلات وقت مع الاخذ في الاعتبار ان Selective Search خزارمية لايمكن ثابتة لايمكن تعليمها وهذا ربما يقود الى اقتراحات مناطق خاطئة. أيضٌا هناك بعض Region المكرره والتي اصلُا تم حسابها مسبقًا ويتم حسابها مرة أخرى.
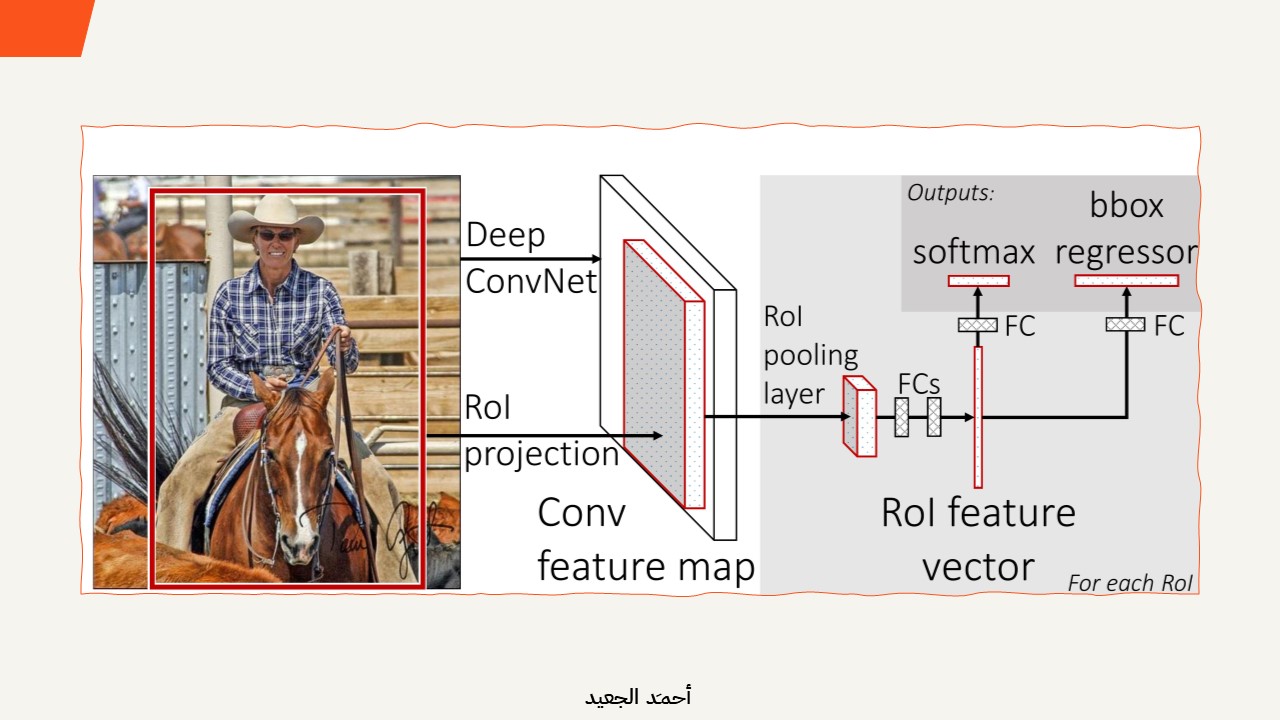
يمكن تشبيه الصورة بقطعة من البازل، ومناطق الكائنات المحتملة بقطع البازل الفردية. يقوم R-CNN بتحليل كل قطعة مستقلة. أما Fast R-CNN، فيقوم أولاً بتحليل البازل بأكمله، ثم يستخدم طبقة تجميع RoI لاستخراج الميزات ذات الصلة من قطع معينة “مثيرة للاهتمام” (الكائنات المحتملة). يوفر هذا التحليل المشترك الوقت ويحسن الدقة.
طبقة ROI Pooling
في Fast R-CNN، تقنية ROI Pooling (تجميع مناطق الاهتمام) هي بمثابة طبقة مسؤولة عن تحويل مناطق الاهتمام Regions of Interest (ROI) – أو المقاطع المحددة في الصورة والتي يحتمل احتواؤها على كائن Object – إلى حجم أو شكل موحد قكما تلاحظ في البُنية الخاصة بـFast R-CNN في الأعلي, طبفة ROI متبوعة بـFully Connect Layer تحتوي علة ابعاد ثابته ولذلك احتجنا الى هذه الطبقة بعدها يمكن تمريره للخطوات اللاحقة في عملية تحليل الصورة:
- مقترحات المناطق (Region Proposals): يبدأ النموذج (في حالة Fast R-CNN) التي تحدد أجزاء في الصورة يُحتمل أن تحتوي على كائنات.
- تقسيم الشبكة (Grid Division): يتم تقسيم كل ROI بشكل افتراضي إلى شبكة من الخلايا بمقاس محدد (مثلا شبكة 32×32).
- تطبيق Max Pooling: في كل خلية من الخلايا التي قمنا بتقسيمها، تقوم تقنية ROI pooling بأخذ القيمة القصوى (Max Pooling) لتمثيل هذه الخلية
- الإخراج بحجم ثابت: الناتج هو مصفوفة ذات حجم ثابت بغض النظر عن الحجم الأصلي لمناطق الاهتمام ROI وذلك لأن تقسيمنا للشبكة كان معياريا في كل حالة.
لماذا ROI Pooling؟
- الحفاظ على الحجم الثابت: بعض طبقات الشبكات العصبية تتطلب مدخلات بحجم ثابت. تقوم الـ ROI Pooling بتحويل المقاطع المُقترحة ROIs، ذات الأحجام المختلفة، إلى صيغة موحدة يمكن للطبقات الأخرى التعامل معها.
- تحسين السرعة : بدلاً من المعالجة المتكررة لمناطق الصورة ذات الأحجام المختلفة، يتم تحويل الـ ROIs لحجم موحد وتتم المعالجة عليها مرة واحدة مما يزيد من كفاءة المودل.
الزبدة
تعتبر تقنية ROI Pooling تحسينًا هامًا تم تقديمه في نموذج Fast R-CNN لمعالجة قيود موجودة في النماذج السابقة ولتحسين سرعة ودقة عمليات اكتشاف الكائنات.
بالإضافة إلى ذلك، بدلاً من تدريب العديد (SVMs) لتصنيف كل فئة من فئات الكائنات، أصبحنا نستخدم طبقة واحدة من نوع Softmax تنتج احتمالات الفئة مباشرةَ. والآن، أصبح لدينا شبكة عصبية واحدة فقط للتدريب، بدلاً من شبكة عصبية واحدة والعديد من نماذج SVMs.
Faster R-CNN
تغلب طراز Faster R-CNN على الاختناق الحاصل بسبب البحث الانتقائي (Selective Search) عبر توظيف شبكة عصبونية لتوليد مقترحات المناطق (region proposals). نجحت شبكة مقترحات المناطق (RPN) في تقليل زمن الاستجابة بمقدار عشرة أضعاف، مما أتاح للنموذج العمل في الوقت الفعلي (real-time). وأثبتت الشبكة كفاءة فائقة لاعتمادها على خرائط الميزات (feature maps) على عكس البحث الانتقائي الذي يستخدم بكسلات الصورة. والأهم من ذلك، لا تشكل شبكة RPN عبئًا إضافيًا يُذكر نظرًا لمشاركة خرائط الميزات بينها وبين باقي مكونات الشبكة.
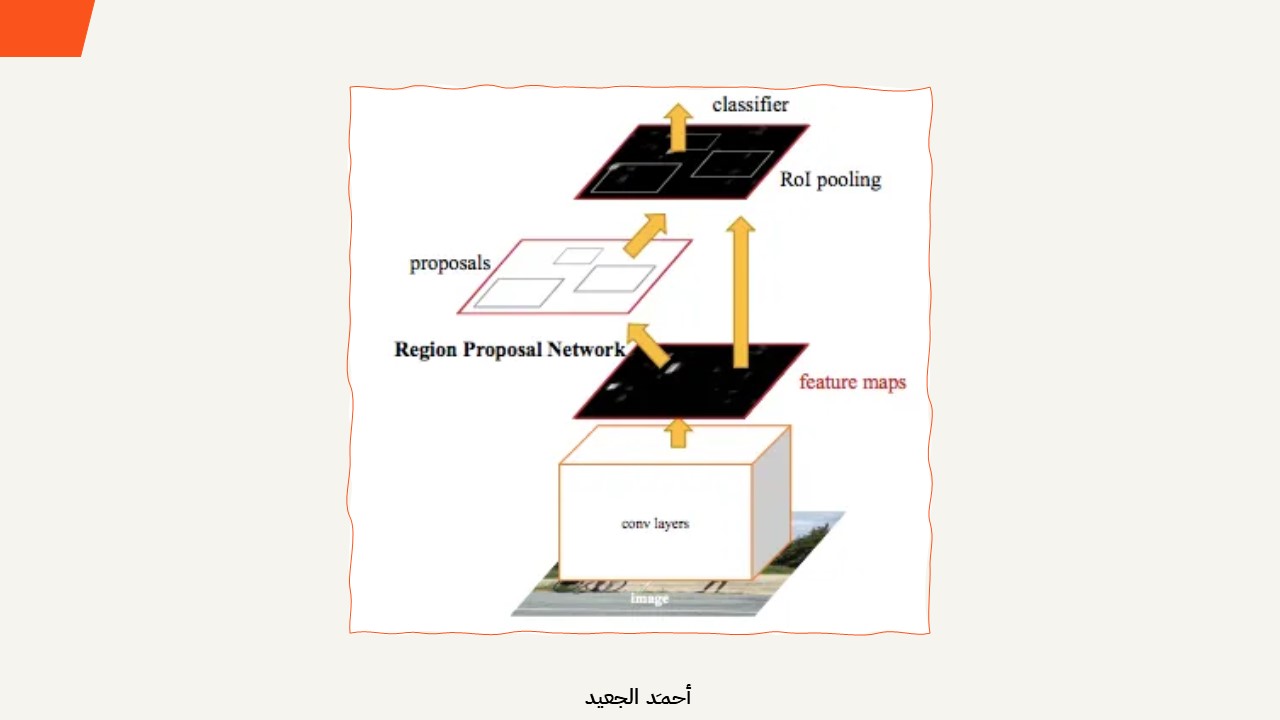
Region Proposal Network (RPN).
شبكة مقترح المناطق (RPN) هي شبكة التفافية كاملة (fully convolutional network) تتنبأ بحدود الأجسام من خلال التعلم من خرائط الميزات (feature maps) المستخرجة من شبكة أساسية. ولديها مصنف (classifier) يعيد احتمالية المنطقة (أي احتوائها على جسم) ومُراجع (regresser) يعيد إحداثيات الصناديق المحيطة (bounding boxes) للأجسام. سأفوم بشرح خطواتها بشكل مبسط:
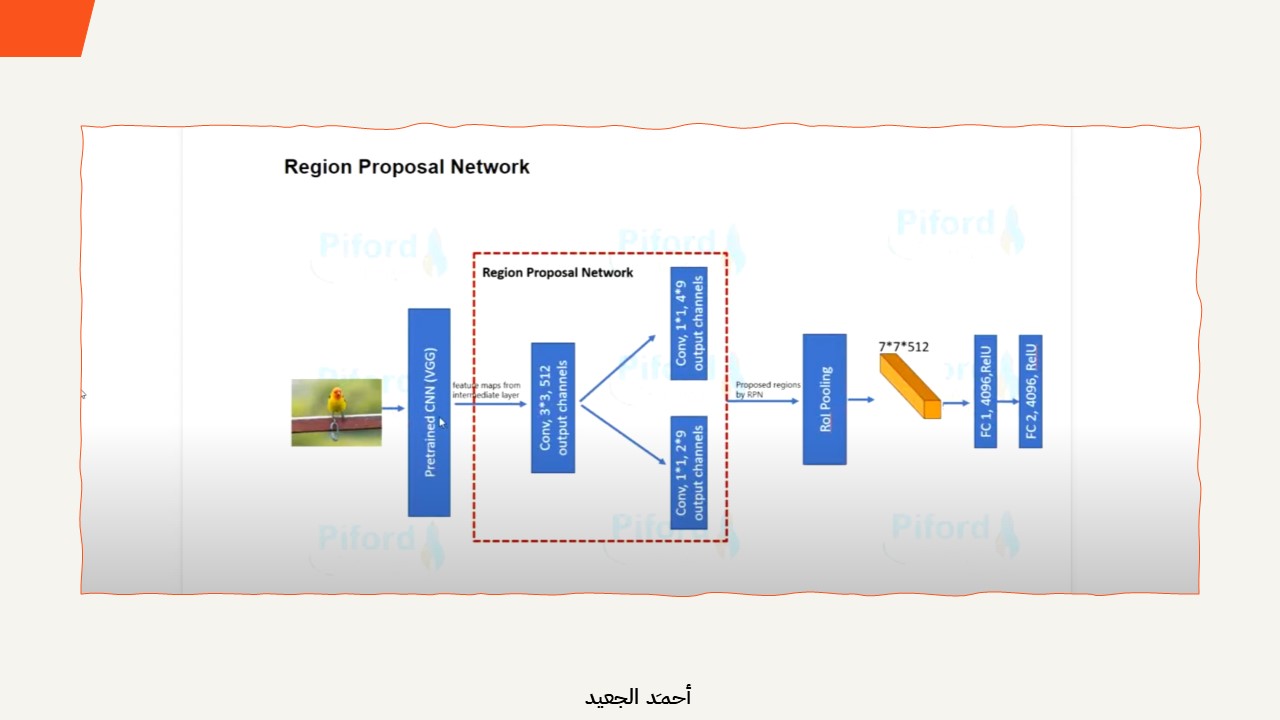
- المدخل: تأخذ RPN صورة كمدخلات.
- استخراج الميزات (Feature Extraction): تمرر الـ RPN الصورة عبر شبكة عصبية التفافية مسبقة التدريب (مثل VGG، ResNet) لاستخراج خريطة الميزات Features Map.
- Sliding Window: تمرر الـ RPN نافذة صغيرة فوق خريطة الميزات للنظر في الميزات المحلية.
- Anchors: في كل موضع للنافذة المنزلقة، تستخدم الـ RPN مجموعة من الصناديق المحيطة مسبقة التحديد ذات الأحجام ونسب العرض إلى الارتفاع المختلفة تسمى “المراسي” كاقتراحات أولية لموقع الجسم.
- التصنيف (Classification): تقوم الـ RPN بتصنيف كل مرساة (anchor) لتحديد احتمال احتوائها على كائن (مقابل الخلفية).
- Bounding Box Regression : تعدل الـ RPN حدود كل Anchor لتلائم بشكل أفضل المنطقة المحتملة التي تضم Object.
- اقتراحات المناطق (Region Proposals): تستخدم الـ RPN التصنيفات Boundary Boxes المصقولة لإنشاء مجموعة من اقتراحات المناطق عالية الجودة المحتمل احتوائها على Objects.
- Object Detector: تمرر مقترحات المناطق إلى شبكة منفصلة للكشف عن Objects تقوم بالتصنيف النهائي ووضع Boundary Boxes للكائنات المكتشفة Objects Detection.
من الجدير بالذكر أنه كجزء من نموذج Faster R-CNN، يتم تدريب شبكة اقتراح المناطق (RPN) بشكل مشترك مع باقي النموذج. وبعبارة أخرى، فإن دالة الهدف (objective function) لـ Faster R-CNN لا تشمل فقط تنبؤ الفئة (class) و الصندوق المحيط (bounding box) في اكتشاف الكائن (object detection)، ولكنها تشمل أيضًا التصنيف الثنائي (binary class) وتنبؤ الصندوق المحيط (bounding box) لـ anchor boxes في شبكة اقتراح المنطقة RPN. ونتيجة للتدريب المتكامل (end-to-end training)، تتعلم RPN كيفية إنشاء مقترحات مناطق عالية الجودة، للحفاظ على الدقة في اكتشاف الكائنات بعدد مخفض من مقترحات المنطقة التي يتم تعلمها من البيانات.
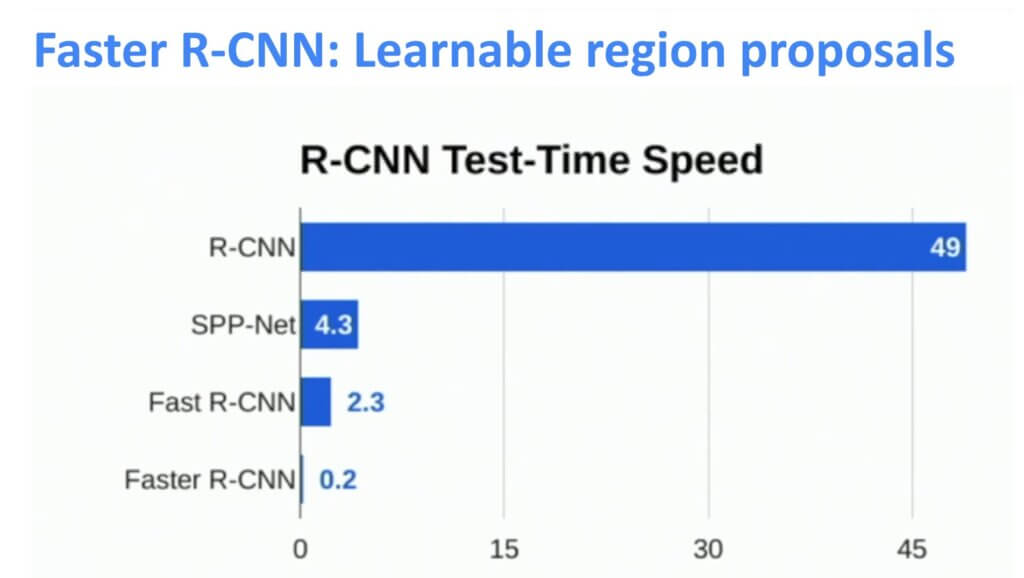
هنا مقارنة توضح كيف تطورت سرعة النماذج الثلاثة السابقة
## Faster R-CNN في PyTorch
في هذا القسم، سنوضح ببساطة كيفية استخدام وتطبيق شبكة R-CNN في بيئة PyTorch. قد تكون عملية البرمجة الكاملة لهذه الشبكة معقدة وتتضمن تفاصيل كثيرة، لذلك سنكتفي باستخدام الدوال (functions) والنماذج الجاهزة (built-in models) المتوفرة في PyTorch. سنقوم باستخدام النموذج وايضُا رسم bounding Box على الكائن Object
import torch
import numpy as np
import matplotlib.pyplot as plt
from torchvision.models.detection import fasterrcnn_resnet50_fpn_v2
from torchvision.io import read_image
from torchvision.utils import draw_bounding_boxes
فقط قمنا بإضافة النماذج من Pytorch الأن سنقوم بكتابة دالة لعرض الصورة
def show(imgs):
if not isinstance(imgs, list):
imgs = [imgs]
fig, axs = plt.subplots(ncols=len(imgs), squeeze=False)
for i, img in enumerate(imgs):
img = img.detach()
img = F.to_pil_image(img)
axs[0, i].imshow(np.asarray(img))
axs[0, i].set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
سنقوم باستحدام هذه الصورة لرسم bounding box حول الحصان

img = read_image(".....")
show(img)
سنقوم بكتابة دالتين مساعدة لمعالجة الصورة وتنفيذ النموذج
def preprocess_image(image, transforms):
return transforms(image)
def perform_detection(model, image):
model.eval()
return model([image])
الأن سنقوم بكتابة النموذج والنتائج المتوقعة
transforms = weights.transforms()
images = preprocess_image(img, transforms)
model = fasterrcnn_resnet50_fpn(pretrained=True)
model = model.eval()
predictions = perform_detection(model, images)
predictions
predictions سيكون عبارة عن قائمة تحتوي على:
- boxes: إحداثيات الصندوق المحيط للأشياء التي تم اكتشافها.
- labels: تسميات الفئة لكل كائن تم اكتشافه.
- scores: درجات الثقة لكل عملية اكتشاف.

الان سنقوم برسم هذه الاحداثيات على الصورة ونشوف النتيجة
score_threshold = 0.9
d = draw_bounding_boxes(img, boxes=predictions[0]['boxes'][predictions[0]['scores'] > score_threshold], width=4, colors='red')
show(d)
ستكون النتيجة بهذا الشكل

ختامًا
تمثل نماذج R-CNN تقدمًا ملموسًا في معالجة مهمة اكتشاف الكائنات (object detection). توفر سلسلة هذه النماذج ، من R-CNN الأصلي إلى التطويرات الأحدث مثل Faster R-CNN و Fast R-CNN، قفزات نوعية في الدقة والكفاءة مقارنة بالأساليب التقليدية. إن قدرتها على تحديد مواقع متعددة للكائنات بدقة داخل الصور ومقاطع الفيديو، حتى في البيئات المعقدة، تجعلها قيمة بشكل خاص لتطبيقات العالم الحقيقي.
في الختام، غيّرت R-CNN نماذج Object Detection عن طريق إدخال مفهوم الشبكات التي تعتمد على المناطق. من خلال التركيز على مناطق الاهتمام واستخدام اقتراحات المناطق، تحسنت بشكل كبير كفاءة مهام Object Detection. ومع ذلك، كانت تعاني من عيوب مثل عدم الكفاءة الحسابية وبطء سرعة المعالجة.
قام Fast R-CNN بمعالجة هذه المشاكل عن طريق إدخال ابتكارات مثل طبقة ROI pooling، التي سمحت بالحساب المشترك بين اقتراحات المناطق وتحسين كل من السرعة والدقة. بالإضافة إلى ذلك، استبدل الحاجة إلى عدة مصنفات SVM بطبقة softmax واحدة، مما بسط عملية التدريب.
أضاف Faster R-CNN مزيدًا من الكفاءة لObject Detection عن طريق إدخال شبكة اقتراحات المناطق (RPN)، التي خفضت بشكل كبير التكلفة الحسابية عن طريق إنشاء اقتراحات المناطق مباشرةً من خرائط الميزات Features Map. من خلال استخدام anchor boxes المحددة مسبقًا وأداء التصنيف وتعديل حدود bounding box regression، حققت Faster R-CNN قدرة على اكتشاف الأجسام Object في الوقت الحقيقي مع الحفاظ على دقة عالية.
بالمعنى الأساسي، فإن التطور من R-CNN إلى Fast R-CNN وأخيرًا إلى Faster R-CNN يعكس الجهود المستمرة في مجال رؤية الحاسوب لتطوير خوارزميات أسرع وأكثر دقة وكفاءة لObject Detection. لقد وفرت هذه التطورات الطريق لتطبيقات مختلفة في مجالات مثل القيادة الذاتية والمراقبة والواقع المعزز، مما يشكل خطوات كبيرة نحو تحقيق الإمكانات الكاملة للذكاء الاصطناعي في مهام التعرف البصري visual recognition tasks.
المصادر
14.8. Region-based CNNs (R-CNNs) — Dive into Deep Learning 1.0.3 documentation (d2l.ai)
Selective Search Explained | Papers With Code
What is R-CNN? (roboflow.com)
Region of Interest Pooling. A Technique which allowed a new… | by Sambasivarao. K | Towards Data Science
ROI pooling (youtube.com)






