

في عصرنا الرقمي الحالي، أصبحت البيانات هي الثروة الجديدة والمحرك الرئيسي لنجاح العديد من التطبيقات القائمة على التعلم الآلي. من تطبيقات التعرف على الوجوه إلى التوصيات الشخصية والتشخيصات الطبية، تعتمد هذه الحلول بشكل كبير على توافر كميات هائلة من البيانات لتدريب نماذجها. ومع ذلك، فإن جمع وتبادل البيانات الحساسة، مثل البيانات الصحية أو المالية، على نطاق واسع يثير العديد من المخاوف المتعلقة بالخصوصية والأمان. هنا يأتي دور تقنية Federated Learning لتوفير حلاً فعالاً لهذه المشكلة.
Federated Learning، أو ما يعرف باسم التعلم الموزع، هو طريقة مبتكره في مجال التعلم الآلي يتيح تدريب نماذج التعلم الآلي على بيانات موزعة عبر أجهزة متعددة دون الحاجة إلى نقل البيانات إلى موقع مركزي. بدلاً من ذلك، يتم تدريب النموذج المحلي على كل جهاز باستخدام البيانات المحلية، ثم يتم دمج التحديثات من جميع الأجهزة لتحسين النموذج العام.
تتميز عملية التدريب في Federated Learning بعدة خطوات رئيسية. أولاً، يتم إنشاء نموذج تعلم آلي أولي على الخادم المركزي. بعد ذلك، يتم توزيع هذا النموذج على الأجهزة المشاركة، حيث يتم تدريبه على البيانات المحلية لكل جهاز. بعد ذلك، يتم إرسال التحديثات المحلية من كل جهاز إلى الخادم المركزي، حيث يتم دمجها لتحسين النموذج العام. يتكرر هذا العملية بشكل تكراري حتى يتم الوصول إلى النموذج النهائي المطلوب.
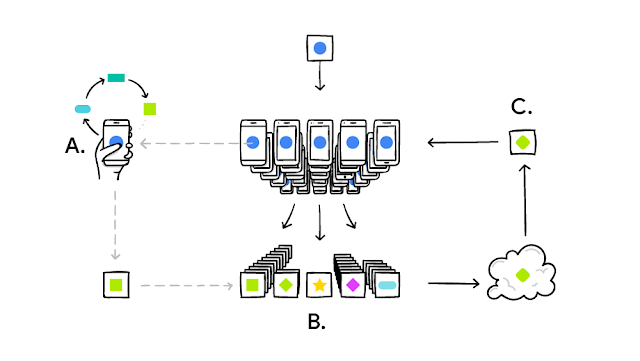
كيف تتم هذه العملية!
-
تقسيم البيانات بين الأجهزة:
في Federated Learning، يتم توزيع البيانات عبر مجموعة من الأجهزة المشاركة، حيث يتم تخزين البيانات المحلية على كل جهاز. هذا التقسيم للبيانات يمكن أن يكون عشوائيًا أو بناءً على خصائص معينة، مثل الموقع الجغرافي أو نوع البيانات. على سبيل المثال، في حالة تطبيق طبي، يمكن تخزين بيانات المرضى في المستشفى الأول على أجهزة ذلك المستشفى، وبيانات المرضى في المستشفى الثاني على أجهزة مختلفة. -
دمج التحديثات من الأجهزة المختلفة:
بعد تدريب النماذج المحلية على كل جهاز، يتم إرسال التحديثات (مثل وزون النموذج) إلى الخادم المركزي. هناك عدة طرق لدمج هذه التحديثات، مثل:
- Federated Averaging: يتم حساب متوسط التحديثات من جميع الأجهزة وتطبيقه على النموذج المركزي.
- Weighted Averaging: يتم إعطاء أوزان مختلفة للتحديثات من الأجهزة المختلفة بناءً على عوامل مثل حجم البيانات أو جودة النموذج المحلي.
- Secure Aggregation: يتم دمج التحديثات بطريقة آمنة باستخدام تقنيات مثل Homomorphic encryption للحفاظ على سرية البيانات.
التشفير المتماثل هو شكل من أشكال التشفير يسمح بإجراء العمليات الحسابية على البيانات المشفرة دون الحاجة إلى فك تشفيرها أولاً.
مفهوم التشفير المتماثل

TensorFlow Federated (TFF): Machine Learning on Decentralized Data (TF Dev Summit ‘19) (youtube.com)
- التعامل مع البيانات غير المتجانسة:
في حالة وجود اختلافات كبيرة في توزيع البيانات عبر الأجهزة، قد يواجه Federated Learning تحديات في تدريب نماذج دقيقة. لمعالجة هذه المشكلة، هناك عدة استراتيجيات يمكن استخدامها:
- Transfer Learning: يمكن استخدام نماذج مدربة مسبقًا على بيانات عامة كنقطة انطلاق، ثم إجراء تدريب إضافي باستخدام Federated Learning على البيانات المحلية.
- Data Augmentation: يمكن تطبيق تقنيات مثل الدوران والتحجيم على البيانات لزيادة التنوع وتقليل التحيز.
- Personalized Federated Learning: في هذا النهج، يتم تدريب نماذج مخصصة لكل جهاز باستخدام البيانات المحلية، بالإضافة إلى النموذج العام المشترك.
- ضمان سرية البيانات:
أحد المزايا الرئيسية لـ Federated Learning هو الحفاظ على خصوصية البيانات. ومع ذلك، لا تزال هناك مخاوف متعلقة بإمكانية استنتاج البيانات الأصلية من التحديثات المرسلة. لمعالجة هذه المشكلة، يمكن استخدام تقنيات مثل:
- Differential Privacy: يتم إضافة ضوضاء عشوائية إلى التحديثات لإخفاء التفاصيل الدقيقة للبيانات الأصلية.
- Secure Aggregation: كما ذكرنا سابقًا، يتم دمج التحديثات باستخدام تقنيات التشفير الآمنة لمنع الكشف عن البيانات الفردية.
- Homomorphic Encryption: يتم تشفير البيانات والعمليات الحسابية بحيث يمكن إجراء العمليات على البيانات المشفرة دون الحاجة إلى فك التشفير.
تطبيقات Federated Learning
-
في مجال الرعاية الصحية، يمكن استخدام Federated Learning لتدريب نماذج التشخيص الطبي باستخدام بيانات المرضى من مستشفيات مختلفة دون الكشف عن معلومات حساسة. على سبيل المثال، قامت شركة Owkin بتطوير نظام يستخدم Federated Learning لتدريب نماذج التنبؤ بمخاطر سرطان الثدي باستخدام بيانات من مستشفيات متعددة في فرنسا.
-
في المجال الصناعي، تستخدم شركة Siemens تقنية Federated Learning لتحسين أداء الآلات والمعدات باستخدام بيانات من أجهزة متعددة في مصانع مختلفة. حيث يتم تدريب النماذج المحلية على البيانات من الآلات في كل موقع، ثم يتم دمج التحديثات لتحسين النموذج العام للصيانة الوقائية والتنبؤ بالأعطال.
-
في مجال المدن الذكية، تعمل شركة Nvidia على تطوير حلول للتعلم الموزع لتحسين إدارة حركة المرور وكفاءة استهلاك الطاقة. حيث يتم استخدام بيانات من كاميرات المراقبة وأجهزة استشعار المرور والطقس في مناطق مختلفة لتدريب نماذج التنبؤ والتحكم دون الحاجة إلى نقل البيانات إلى موقع مركزي.
هذه هي بعض الأمثلة على كيفية تطبيق Federated Learning في مجالات مختلفة، مما يوضح إمكاناتها الواسعة في تمكين التطبيقات الذكية مع الحفاظ على خصوصية البيانات.
هذا النهج له العديد من المزايا الرئيسية. أولاً، يحافظ على خصوصية البيانات حيث لا يتم نقل البيانات الحساسة إلى موقع مركزي. ثانياً، يقلل من متطلبات نقل البيانات وبالتالي يحسن الكفاءة والموارد اللازمة. ثالثاً، يسمح بتدريب نماذج أكثر دقة وشمولية باستخدام بيانات متنوعة من مصادر متعددة.
اطر العمل
لتسهيل تطوير وتنفيذ تطبيقات Federated Learning، ظهرت العديد من أطر العمل المفتوحة المصدر مثل TensorFlow Federated من Google، PySyft من OpenMined، و Federated AI Technology Enabler (FATE) من Webank. تقدم هذه الأطر بنية أساسية مرنة وآمنة لتطوير نماذج موزعة وإدارة دورة حياة التدريب والاستدعاء.
TensorFlow Federated، على سبيل المثال، هو إطار عمل مبني على TensorFlow يوفر واجهات برمجة تطبيقات (APIs) وأدوات لتطوير وتنفيذ تطبيقات Federated Learning بشكل آمن وفعال. يدعم العديد من خوارزميات التدريب الموزع، بما في ذلك التدريب الموزع والتدريب المتكرر.
من ناحية أخرى، يركز PySyft على توفير بنية أساسية مفتوحة المصدر للحوسبة الموزعة الخاصة والآمنة. يسمح للمطورين بتطوير نماذج التعلم الآلي وتدريبها على بيانات موزعة عبر أجهزة متعددة مع الحفاظ على الخصوصية والأمان.
أما FATE، فهو إطار عمل شامل لتطوير وتشغيل تطبيقات التعلم الآلي الموزعة والخاصة. يدعم العديد من خوارزميات التعلم الآلي، بما في ذلك التعلم العميق والتعلم الآلي التقليدي، ويوفر أدوات لإدارة دورة حياة التطبيق بأكملها.
مثال لاستخدام FL مع TF
سنقوم باستخدام TensorFlow Federated (TFF) للقيام بمحاكاة بسيطة لتوضيح مفهوم Federated Learning ويكون هذا منطلق لك في استخدامه في تدريب بيانات الخاصة.
import collections
import tensorflow as tf
import tensorflow_federated as tff
- collections: مكتبة Python قياسية توفر أنواع بيانات متخصصة مثل
OrderedDict. - tensorflow (tf): مكتبة التعلم الآلي الشهيرة، المستخدمة لبناء نماذج Keras.
- tensorflow_federated (tff): مكتبة TFF توفر الوظائف اللازمة لتنفيذ خوارزميات Federated Learning.
تحميل بيانات المحاكاة
source, _ = tff.simulation.datasets.emnist.load_data()
- يستخدم
tff.simulation.datasets.emnist.load_dataلتحميل مجموعة بيانات EMNIST، وهي مجموعة بيانات شائعة الاستخدام للتعرف على الأرقام المكتوبة بخط اليد. وهي مثالية لتوضيح مفاهيم Federated Learning لأغراض التدريب.
تهيئة بيانات الأجهزة
def client_data(n):
return source.create_tf_dataset_for_client(source.client_ids[n]).map(
lambda e: (tf.reshape(e['pixels'], [-1]), e['label'])
).repeat(10).batch(20)
- تحدد دالة
client_dataكيفية تجهيز البيانات لكل جهاز محدد في بيئة التعلم الموزع المحاكى.- تقسيم البيانات لكل جهاز (Client): يستخدم
source.create_tf_dataset_for_clientلتقسيم البيانات بين مجموعة افتراضية من الأجهزة. - التهيئة: يُجهّز كل عنصر بيانات (وهو صورة) بتغيير شكله
e['pixels']وحفظه مع التصنيف الحقيقيe['label']. - الإعادة والتجميع ((Repeat and Batch): تتكرر مجموعة البيانات وتُقسّم إلى مجموعات أصغر (batches) لتحسين عملية التدريب.
- تقسيم البيانات لكل جهاز (Client): يستخدم
بيانات التدريب
train_data = [client_data(n) for n in range(3)]
- تقوم بتجهيز بيانات التدريب عن طريق إنشاء قائمة من مجموعات البيانات لثلاثة (أجهزة) مُحاكاة باستخدام دالة
client_dataالمحددة مسبقًا.
نموذج Keras
keras_model = tf.keras.models.Sequential([
tf.keras.layers.Dense(
10, tf.nn.softmax, input_shape=(784,), kernel_initializer='zeros')
])
- يتم بناء نموذج Keras بسيط يستخدم للتصنيف. لديه طبقة كثيفة مع 10 نيرونات (واحدة لكل فئة رقم) لتحديد الرقم المكتوب بخط اليد.
نموذج TFF
tff_model = tff.learning.models.functional_model_from_keras(
keras_model,
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(),
input_spec=train_data[0].element_spec,
metrics_constructor=collections.OrderedDict(
accuracy=tf.keras.metrics.SparseCategoricalAccuracy))
- يحوّل نموذج Keras الذي تم إنشاؤه مسبقًا إلى نموذج TFF متوافق مع Federated Learning. تحدد الوسائط
loss_fnوmetrics_constructorدالة الخسارة ومقاييس التقييم لعملية التدريب.
التدريب الموزع
trainer = tff.learning.algorithms.build_weighted_fed_avg(
tff_model,
client_optimizer_fn=tff.learning.optimizers.build_sgdm(learning_rate=0.1))
- يقوم بإنشاء خوارزمية
trainerباستخدامweighted_fed_avg، وهي خوارزمية تدريب موزع شائعة تحسب المتوسط المرجح لتحديثات النماذج من الاجهزة. كما تستخدم مُحسّن التدرج العشوائي (SGD).
ملاحظة: هذا مثال أساسي جدًا، هناك خوارزميات ومُحسّنات أكثر تقدمًا مدعومة في TFF.
الكاتب
الخاتمة
على الرغم من فوائدها العديدة، إلا أن Federated Learning لا تزال تواجه بعض التحديات، مثل ضمان سرية التدريب وأمان الاتصالات بين الأجهزة، وكذلك التعامل مع البيانات غير المتجانسة والضوضاء بشكل أكثر فعالية. كما أن هناك حاجة إلى مزيد من البحث لتحسين كفاءة الخوارزميات وزيادة قدرتها على التعامل مع البيانات غير المتوازنة.
ومع ذلك، فإن Federated Learning تمثل خطوة مهمة نحو تحقيق التوازن بين الاستفادة القصوى من البيانات والحفاظ على الخصوصية. مع استمرار تطور هذه التقنية والأطر العمل المرتبطة بها، من المتوقع أن تلعب دوراً محورياً في تمكين التطبيقات الذكية والآمنة في المستقبل، خاصة في المجالات الحساسة مثل الرعاية الصحية والأمن السيبراني.





