في سياق تحليل واحصاء البيانات , البيانات المفقودة تشير الى غياب البيانات من متغير او اكثير في مجموعة البيانات. عند جمع وتسجيل البيانات, ليس من الغريب ان يكون هناك بعض الفقد في الحقول او السمات سواء كان ذلك الفقد حدث بالصدفة او بشكل متعمد.
من الضروري كعالم بيانات او محلل لها ان تعرف ماهي القيم المفقودة واسبابها وكيفية معالجتها بشكل مناسب, لان وجودها او معالجتها بشكل غير صحيح يؤثر بشكل كبير على جودة النتائج وموثوقيتها. هذا يقودنا الى مشكلة أخرى وهي تحيز البيانات الذي يؤثر بشدة على النتائج الإحصائية او خوارزميات تعلم الآلة.
تحيز البيانات (Data Bias) هو مفهوم يرتبط بعلم البيانات والاحصاء ويشير إلى التحيز الذي يظهر في مجموعة البيانات نفسها أو في العمليات التي تجمع البيانات. ويكون التحيز عندما يكون هناك تمييز أو انحياز في الطريقة التي تم بها جمع البيانات أو التغطية العينية للمجتمع أو الظواهر التي تدرسها.
كعالم بيانات او محلل بيانات تقوم باستثمار الكثير من الوقت في معالجة البيانات وهذا يقود الى تحسن دقة التحليل والتصور الكامل للبيانات, وزيادة موثوقية الاستناتاجات. وهذا بالطبع يمكُن صانعي القرار من اتخاذ خطوات واضحة ومدروسة مستندين على بيانات موثوقة في علاقة طردية.
ليست جميع البيانات في الدروس او المقالات كما ستشاهد في بيئة العمل.
سنحاول هنا تغطية عدة جوانب لهذه المشكة من حيث اسبابها وانواعها, مالتحديات التي ريما تواجهك في معالجتها, ايضًا سنقوم بمعرفة عدة تقنيات لتقليل أثر الفقد للبيانات مع بعض الأمثلة التي باذن الله ستكون مرجع او منطلق لك في رحلتك لاستخراج الحقائق الموثوقة.
انواع البيانات المفقودة
مفقودة بشكل عشوائي تمامُا (MCAR) : يحدث هذا الفققد بشكل عشوائي تمامُا ويكون هذا الفقد مستقل عن اي متغير آخر في مجموعة البيانات. مثال : تخيل انك تجمع استطلاع من المستخدمين على الانترنت, وبسبب مشاكل تقنية لدى البعض تم فقد بعض البيانات خلال الاستطلاع او تم تجاوز بعض الاسئلة. اذا لاحظت هنا ان البيانات تم فقدها بشكل عشوائي وغير مرتبط ابدَا باي متغير آخر. مع انك تلاحظ ان هناك فقد للبيانات لكن عند قيامك بنوزيعها تكون غير مرتبطة او متحيزة الى اي متغير أخر.
مفقودة بشكل عشوائي (MAR) : قد يكون هذا المسمى غير دقيق بعض الشئ, لان البيانات هنا لم تفقد بشكل عشوائي. هنا البيانات فقدت في متغير متاثره بمعامل أخر, وهنا تكون البيانات مختلفه بشكل منهجي عن البيانات التي جمعتها وتستطيع تفسير لماذا هذه البيانات مفقوده بالاعتماد على مقياس او مقاييس آخرى. وبمعنى آخر، نحن قادرون على فهم وتفسير سبب نقص البيانات باستخدام المعلومات المتاحة لدينا عن متغيرات أخرى. مثال : لو كان هناك باحثون يريدون تجربة عقار طبي جديد, ولكن اتضح ان هناك بعض المشتركين فوتوا بعض المواعيد بسبب بعد المسافة. هنا نقول ان السبب هو بعد المسافة وليس بسبب عدم استجابتهم للعقار الطبي.
مفقودة بشكل ليس عشوائي (MNAR): هنا الفقد في البيانات يعتمد على البيانات المرصوده نفسها, مما يؤدي الى تحيز في البيانات. مثال : لو قمت بجمع استطلاع عن دخل الاشخاص, ووقام بعض الافراد بتجاوز هذا السؤال عمدًا بسبب عدم رغبتهم بالفصح عن دخلهم العالي. هنا البيانات المفقودة تعتمد على المتغير بحد ذاته وهو في هذه الحالة الدخل.
مثال:
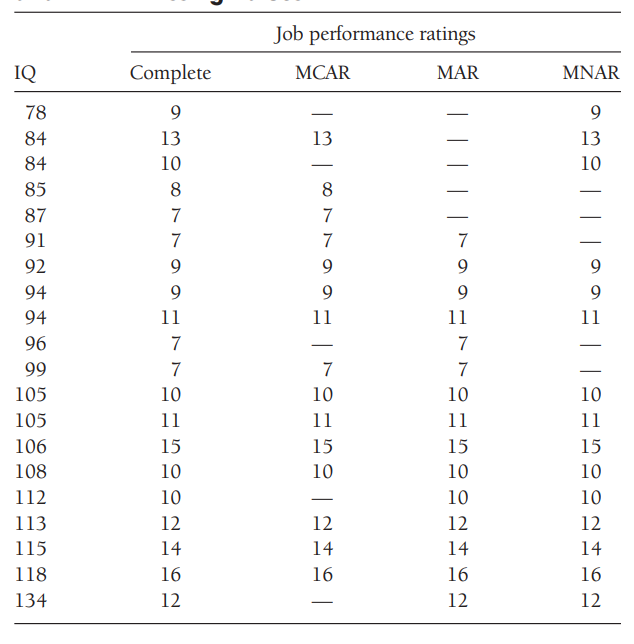
مصدر الجدول كتاب Applied Missing Data Analysis
صٌممت البيانات الموجودة في الجدول السابق لتقليد سيناريو اختبار الموظفين، يتكون الجدول من خمسة اعمدة, من اليسار لليمين العمود الاول هو اختبار IQ يليه شكل البيانات “لو” كانت كاملة بعدها تأتي الأعمدة الخاصة بانواع البيانات المفقودة. حيث يقوم المتقدمون للوظائف بإجراء اختبار ذكاء خلال مقابلات التوظيف، ويتم تقييم أدائهم في العمل من قِبل المشرف بعد فترة تجريبية تستمر لمدة 6 أشهر.
مفقودة بشكل عشوائي (MAR)
نفترض أن الشركة استخدمت درجات الذكاء كمقياس اختيار ولم تقم بتوظيف المتقدمين الذين حصلوا على درجات تقع في الربع الأدنى من توزيع اختبار الذكاء. يمكنك ملاحظة أن تقييمات أداء العمل في عمود MAR من الجدول السابق غير متوفرة للمتقدمين الذين حصلوا على أدنى درجات الذكاء. وبالتالي، فإن احتمالية عدم وجود تقييم لأداء العمل هي نتيجة فقط لدرجات الذكاء، ولا ترتبط بأداء الموظف الفعلي.
مفقودة بشكل عشوائي تمامُا (MCAR)
الكاتب يشير في الجدول انه قام بحذف ارقام من عمود MCAR بشكل عشوائي, هذه الأرقام العشوائية لا علاقة لها من قريب او بعيد بالاداء الوظيفي او اختبار الذكاء. من خلال ملاحظتك سترى توزيع السجلات المفقودة تم بشكل عشوائي في اماكن مختلفة في الجدول. ممايعطيك اختلاف عن الحالة السابقة انه لايوجد نمط معين لهذا الفقد.
مفقودة بشكل ليس عشوائي (MNAR)
افرض الشركة وظفت جميع ال20 شخص, وبعدين في خلال فترة التجربة قامت بتسريح بعض الموظفين بسبب الاداء الغير مرضي, ستلاخظ في الجدول ان البيانات المفقودة كانت بسبب الاداء المنخفض. هذا يعني ان احتمالية ضياع البياناات هنا بسبب الاداء الوظيفي بحد ذاته حتى بعد اكتمال بيانات اختبار الذكاء.
الأسباب الشائعه للبيانات المفقودة
هنا اكثر من سبب شائع لوجود بيانات مفقودة في مجموعة البيانات. هنا الأكثر شيوعًا:
أخطاء اثناء ادخال البيانات : هناك اخطاء تحدث اثناء جمع البيانات او نسخها او ادخالها.
عدم الاستجابة – عدم المشاركة : في الاستطلاعات او الاستبيانات, المشاركون ربما لا يتفاعلون مع بعض الاسئلة وهذا يقود الى حقول فارغة.
الخصوصية والسرية : بعض الاوقات يقوم المستجيبون او المشاركون بحجب معلومات حساسه لحماية خصوصيتهم.
المشكلات التقنية : خلال جمع البيانات يمكن ان تؤدي المشكلات التقنية مثل الاعطال في المعدات او اخطاء تخزبن البيانات. الى حدوث فقد في البيانات.
تنظيف البيانات والمعالجة المسبقة : اثناء مرحلة تهنئة وتنظيف البيانات قد يتم تحديد قيم معنية على انها متطرفة او غير صالحة وتتم ازالتها.
ترحيل وتكامل البيانات : عند جمع البيانات ودمجها من مصادر مختلفة تؤدي مشكلات الترحيل والتكامل الى ققد في بعض البيانات.
هذه الاسباب على سبيل المثال لا الحصر, هناك العديد والعديد من الاسباب التي تؤدي الى حدوث فقد في البيانات.
عند تجاهل القيم المفقودة في التحليل ، سيتم تضمين الموضوعات ذات السجلات الكاملة فقط. قد يؤدي هذا إلى نتائج متحيزة وفقدان القوة.
Missing data: the impact of what is not there
تحديات التعامل مع البيانات المفقودة
التعامل مع البيانات المفقودة يمكن ان يكون امرًا صعبًا ويشكل عقبات لعلماء البيانات والباحثين, هنا بعض التحديات التي ربما تواجهك.
نتائج متحيزه: اذا لم يتم التعامل مع البيانات المفقودة بشكل صحيح, قد يؤدي ذلك الى استنتاجات مضللة ونتائج غير دقيقة.
تقليل حجم العينة : عندما تحتوي نقاط البيانات على قيم مفقودة يقل حجم العينة الفعال, مما قد يقلل من القوه الاحصائية للتحليل.
التعقيد في احتساب البيانات : قد يكون طريقة معالجة البيانات المفقودة امرُا صعبُا, حيث ان التقنيات المختلفة لها افتراضاتها وقيودها. يمكن يؤدي اختيار الطريقة الخاطئة الى تشويه البيانات.
تعقيد البيانات ونمطها: في المجموعات الكبيره والمعقده من البياناتقد يكون تحديد نمط البيانات المفقوده تحديُا صعبًا, مما يجعل من الصعب تحديد استراتيجية المعالجة المناسبة.
الوقت والموارد: بعض طرق المعالجة للبيانات المفقودة تكون مكلفه للموارد وتتطلب قدرة كبيرة من المعدات للقيام بالعمليات الحسابية, خصوصات في البيانات الضخمة.
التعامل مع اكثر من تقنية للمعالجة : هذا يقود الى إضافة تعقيد إلى تحليل البيانات.
البيانات المفقودة بشكل ليس عشوائي: التعامل مع هذا النوع من البيانات المفقودة الذي سببه هو فقد البيان بحد ذاته يطرح تحدي جديد وهو غياب البيانات غير المعروف اسبابه.
يتطلب منك كعالم بيانات او احصائي الى فهم عميق للبيانات وتجربة اكثر من استراتيجية للتعامل مع هذا الفقد الحاصل في السجلات. يجب عليك مراعاة التأثير المحتمل لأي طريقة معالجة مستخدمة على نتائج التحليل.
تأثير البيانات المفقودة
تحيز النتائج والاستنتاج الخاطئ: البيانات المفقودة تقودك الى نتائج متحيزة واستنتاجات غير دقيقة, ربما لم تفقد هذه البيانات بشكل عشوائي تمامًا وانها قد تكون مرتبطة بمتغير أخر او مجموعة من المتغيرات.
تُقلل حجم العينة وقوة التحليل: تأثر البيانات المفقودة على فعالية مجموعة البيانات, وهذا يقود الى تقليل قوة التحليل, وكما هو معروف حجم العينة الصغير يفشل بشكل او بآخر في اكتشاف التاثيرات الحقيقة او الارتباطات.
التأثير على اداء نماذج الآلة: لا يوجد مجال للشك ان البيانات المفقودة تأثر بشكل كبير على اداء نماذج تعلم الآلة, وايضًا على قدرتها التنبؤئية. من المعروف ان نماذج الألة نمطية الى حد ما, وجود هذه المشكلة تجعل النموذج يعاني لاكتشاف هذه الانماط.
خاتمة
التعامل مع البيانات المفقودة هو أحد الجوانب الحيوية في مجال علم البيانات والذكاء الاصطناعي. إن فهم كيفية التعامل مع البيانات التي تفتقر إلى جزء منها أو كلها يعد عنصرًا أساسيًا للوصول إلى نتائج دقيقة وقرارات موثوقة. يمكن أن يكون عدم توفر البيانات بشكل كامل أمرًا شائعًا في العديد من السيناريوهات، مثل البيانات الطبية، والمسوح الاستقصائية.
في الجزء الثاني، سنستكشف معًا طرق المعالجة الصحيحة للبيانات المفقودة وسنقدم بعض الأمثلة البرمجية لتوضيح الأفكار والتقنيات. سيتيح لنا ذلك فهمًا أعمق لكيفية التعامل مع تلك البيانات وتجاوز التحديات التي قد تواجهنا.