

كعلماء بيانات، من واجبنا الدائم تحسين أداء نماذج الآلة التي طورناها. ربما قد لاحظت، أن النموذج الذي قمت بتدريبه ونشره والذي كان يظهر أداءً ممتازًا في البداية، ومع مرور الوقت بدأ اداء النموذج بالانخفاض. هذا التدهور في أداء النموذج ليس مجرد نتيجة لأخطاء في التحليل أو البرمجة، بل يرتبط بظاهرة معروفة بـ ‘Drift’ أو التحول.
في مرحلة تدريب النموذج، اعتمدت على مجموعة من البيانات التي تم جمعها في وقت سابق، وقد تكون هذه البيانات قديمة أو غير ممثلة بشكل جيد للواقع الحالي. ببساطة، قد تتغير طبيعة البيانات مع مرور الوقت، سواء كان ذلك بسبب تغيير في اتجاهات المستخدمين أو تحولات في السوق أو أحداث غير متوقعة.
هذا التحول في البيانات يمكن أن يؤدي إلى تحديات في أداء النموذج، حيث يفقد النموذج قدرته على التكيف مع التغييرات الجديدة. يمكن أن يتسبب Drift في انخفاض دقة النموذج، مما يعني أن النتائج التي يقدمها قد لا تكون بنفس الجودة التي كانت عليها في البداية.
ومن خلال هذه التحديات, يتطلب الحفاظ على أداء النموذج وتفادي التدهور الناتج عن Drift هو الاستمرار في تحسين وتحديث النموذج بانتظام. يجب تقديم مزيد من البيانات الحديثة وتكرار عمليات التدريب لتعزيز قدرة النموذج على التكيف مع التغييرات البيانية. يعد الإلمام بمفهوم Drift أساسيًا للحفاظ على جودة النموذج وضمان تطابقه مع الواقع المتغير دائمًا.
لماذا يحدث هذا التحول في الاداء؟
تحدث ظاهرة Drift في نماذج الآلة بسبب تغيرات في البيانات التي تم تدريب النموذج عليها أو التي يتعامل معها بعد التدريب في مرحلة التفسيرات (inference). هناك عدة أسباب تشير إلى سبب حدوث هذه التحولات:
- تغير في الظروف البيئية:
- تتغير ظروف البيئة مع مرور الوقت، وهذا يمكن أن يؤدي إلى تغير في نمط البيانات. مثلاً، قد يتغير سلوك المستخدمين، أو قد تطرأ تغييرات في السوق أو الظروف الاقتصادية.
- تحولات في المتغيرات المرتبطة بالبيانات:
- قد تحدث تغييرات في العلاقات بين المتغيرات المستخدمة في تدريب النموذج. هذه التحولات يمكن أن تؤثر على أداء النموذج، خاصة إذا كان يعتمد على تفاصيل دقيقة لتحديد العلاقات بين البيانات.
- تغير في توزيع البيانات:
- قد يحدث تغيير في توزيع البيانات على مر الزمن، حيث قد يزيد أو ينقص تواتر بعض القيم، أو يظهر نمط جديد في البيانات. هذا التحول في توزيع البيانات يؤثر على قدرة النموذج على التعامل مع الأمثلة الجديدة بكفاءة. لنفترض أن لديك نموذج آلي تم تدريبه للتعرف على رسائل البريد الإلكتروني الاحتيالية (التصيد). في مرحلة التدريب، استخدمت مجموعة كبيرة من رسائل البريد الإلكتروني الواردة من مستخدمين في الفترة بين عامي 2021و2022. كان النموذج يظهر أداءً جيدًا وكان فعالًا في التعرف على أساليب الاحتيال التي كانت شائعة في تلك الفترة.
مع مرور الوقت، يبدأ النموذج في التصرف بشكل غريب وأقل فعالية، ويظهر ضعفًا في قدرته على التعرف على رسائل التصيد الحديثة. لماذا يحدث هذا؟ هناك عدة احتمالات وأسباب لحدوث مثل هذه الظاهرة ومنها على سبيل المثال لا الحصر
- تغير في أساليب الهجوم:
- قد يحدث تغير في أساليب الهجوم المستخدمة في رسائل التصيد مع مرور الوقت. ربما ظهرت تقنيات جديدة أو تطورت الطرق الحالية، ولم يتم تدريب النموذج على هذه التقنيات الجديدة.
- تغيير في محتوى البريد الإلكتروني:
- قد تتغير أيضًا محتويات رسائل البريد الإلكتروني مع مرور الوقت. قد تظهر كلمات جديدة أو أنماط جديدة في النصوص، وقد يكون النموذج غير قادر على التعرف على هذه التغييرات.
هناك مثال ايضًا من الحياة الواقعية لأحد شركات الكهرباء المعروفة, كانوا يعتمدون على بيانات سابقة لتنبؤ بعدد الكيلوواط التي يحتاجها سكان مدينة معينة خلال الأشهر القادمة, ولكن حدث مالم يكن في الحسبان وبدأت جائحة كورونا وتم الإغلاق وعمليات الحجر فتغير سلوك المستخدمين في استخدام الكهرباء ومتوسط استهلاكهم وبقائهم في المنزل والكثير من المتغيرات, هذا التأثير غير في توزيع البيانات وأثر على اداء نماذج الآلة مما تسبب سلبًا على وصول الخدمة بالشكل المطلوب للمستخدمين.
أنواع Drift التي يمكن ان تؤثر على اداء نموذج البيانات:
هناك نوعين رئيسين لهذه الظاهرة وكل نوع يندرج تحته عدة تصنيفات ولكل تصنيف قياس وتوزيع يوضح هذه المشكلة.
- تحول المفهوم (Concept Drift):
يحدث تحول المفهوم عندما يكون هناك تغيير في العلاقة بين المتغيرات المدخلة (Independent) والمتغير الهدف (Dependent). بمعنى آخر، يتم تطور المفهوم أو النمط الذي تم تدريب النموذج على التعرف عليه، مما يؤدي إلى توقعات غير دقيقة. وقد قدم Jie Lu, ومن معه في ورقتهم العلمية “Learning under Concept Drift: A Review” عدة انواع فرعية لـتحول المفهوم ويمكن توضيحها في النقاط التالية.يحدث تحول المفهوم عندما يكون هناك تغيير في العلاقة بين المتغيرات المدخلة (Independent) والمتغير الهدف (Dependent). بمعنى آخر، يتم تطور المفهوم أو النمط الذي تم تدريب النموذج على التعرف عليه، مما يؤدي إلى توقعات غير دقيقة. وقد قدم Jie Lu, ومن معه في ورقتهم العلمية “Learning under Concept Drift: A Review” عدة انواع فرعية لـتحول المفهوم ويمكن توضيحها في النقاط التالية
تحول المفهوم التدريجي (Gradual Concept Drift):
التغيرات في سلوك الاحتيال على مر الوقت يمكن اعتبارها مثالًا على تحول المفهوم التدريجي. مع تقدم طرق اكتشاف الاحتيال، يقوم المحتالون بالتكيف وتطوير استراتيجيات جديدة لتفادي أنظمة اكتشاف الاحتيال. قد يجد النموذج الذي تم تدريبه على بيانات تاريخية للمعاملات الاحتيالية صعوبة في تصنيف استراتيجيات جديدة كاحتيال، مما يؤدي إلى إنخفاض أداء النموذج.

- تحول المفهوم المفاجئ (Sudden Concept Drift)
جلبت جائحة COVID-19 تغييرات مفاجئة في سلوك المستهلكين. على سبيل المثال، ارتفع إنفاق المستهلكين على معدات اللياقة البدنية المنزلية، بينما انخفض إنفاقهم على خدمات النقل. قد لا يتنبأ نموذج توقعات الطلب الذي تم تدريبه على بيانات ما قبل الجائحة بتلك التغييرات في عادات المستهلكين، مما يؤدي إلى توقعات غير دقيقة.

- تحول المفهوم المتكرر (Recurring Concept Drift):
الفصول الدورية تعد نموذجًا لتحول المفهوم المتكرر. على سبيل المثال، تزيد مبيعات التجزئة بشكل كبير خلال موسم الأعياد أو في يوم الجمعة البيضاء. قد يقدم نموذج الآلة الذي لا يأخذ هذه التغييرات المتكررة المعروفة في الاعتبار توقعات غير دقيقة خلال هذه الفترات.

تحول البيانات (Data Drift):
يحدث تحول البيانات عندما يكون هناك تغيير في توزيع بيانات الإدخال، حتى لو بقيت العلاقة بين المتغيرات ثابتة. قد يؤدي ذلك إلى عدم تطابق بين بيانات التدريب والبيانات التي يواجهها النموذج أثناء التشغيل (inference).
- يمكن أن يسبب التغيير في التوزيع الديموغرافي، مثل توزيع الأعمار، تحول البيانات. إذا تم تدريب النموذج على بيانات من سكان لديهم توزيع عمري معين وتم نشره لاحقًا في بيئة حيث تغير توزيع الأعمار، قد يؤدي ذلك إلى تراجع أداء النموذج حيث لا يتناسب بشكل صحيح مع توزيع البيانات الحالي.
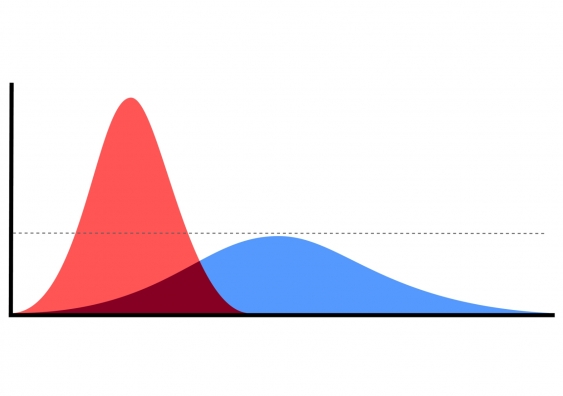
كيف يمكن قياس هذا التحول Drift ؟
يوجد العديد من الاختبارات الإحصائية والخوارزميات التي يمكن ساتخدامها لقياس التحول في البيانات مع مرور الوقت. سأقوم بتوضيح بعض هذه الأساليب بشكل موجز واترك لك التعمق في التفاصيل.
1. اختبار Kolmogorov-Smirnov (K-S) الإحصائي:
الغاية من هذا الإختبار الإحصائي Kolmogorov-Smirnov (K-S) هو التأكد من ان مجموعتي البيانات تأتي من نفس التوزيع Distribuation. يستخدم في المقام الأول لتقييم ما إذا كانت العينة تتوافق مع مجموعة دراسة معينة أو لمقارنة عينتين لأصل مجموعة دراسية مشترك، ويعمل اختبار K-S على افتراض أن التوزيعات المعنية متطابقة. هذا الاختبار جيد جداً في اكتشاف التحول في البيانات الصغيرة الى المتوسطة ويقل اداءه مع عينات البيانات الكبيرة والضخمة.
تفترض الفرضية الصفرية (null hypothesis) أن التوزيعات التي تتم مقارنتها هي نفسها بالفعل. إن رفض هذه الفرضية يعني وجود انحراف في النموذج مما يشير إلى وجود خروج عن التوزيع المتوقع.
هناك العديد من الإختبارات الإحصائية التي تقارن بين توزيع البيانات ومنها:
- Population Stability Index (PSI)
- Wasserstein distance (Earth-Mover distance)
- Kullback-Leibler divergence
- Jensen-Shannon distance
2. استخدام Evidently
سنقوم باستخدام Evidently وهو مكتبة بايثون مفتوحة المصدر تقدم العديد من الخيارات لمراقبة وقياس اداء نموذج الآلة في بيئة الإطلاق, يقدم العديد من الخيارات لمتابعة الاداء لنماذج الآلة وهو موجه لعلملاء البيانات ومهندسي الذكاء الاصطناعي. سنستعرض بعض من الأمثلة وكيفية انتاج التقارير ومتابعتها
from sklearn.datasets import fetch_california_housing
from evidently import ColumnMapping
from evidently.report import Report
from evidently.metrics.base_metric import generate_column_metricsسنقوم باستخدام بيانات اسعار المنازل في كاليفورنيا, سنجري بعض التجارب ونتحقق هل هناك تحول في البيانات او لا.
housing_data.rename(columns={'MedHouseVal': 'target'}, inplace=True)
housing_data['prediction'] = housing_data['target'].values + np.random.normal(0, 5, housing_data.shape[0])سنقوم بانشاء مجموعتي بيانات للمقارنة
reference = housing_data.sample(n=5000, replace=False)
current = housing_data.sample(n=5000, replace=False)الآن سنستعرض كيفية انشاء تقرير يوضح كل متغير توزيعه وهل هناك Drift او لا
report = Report(metrics=[
DataDriftPreset(),
])
report.run(reference_data=reference, current_data=current)سيكون التقرير بهذا الشكل
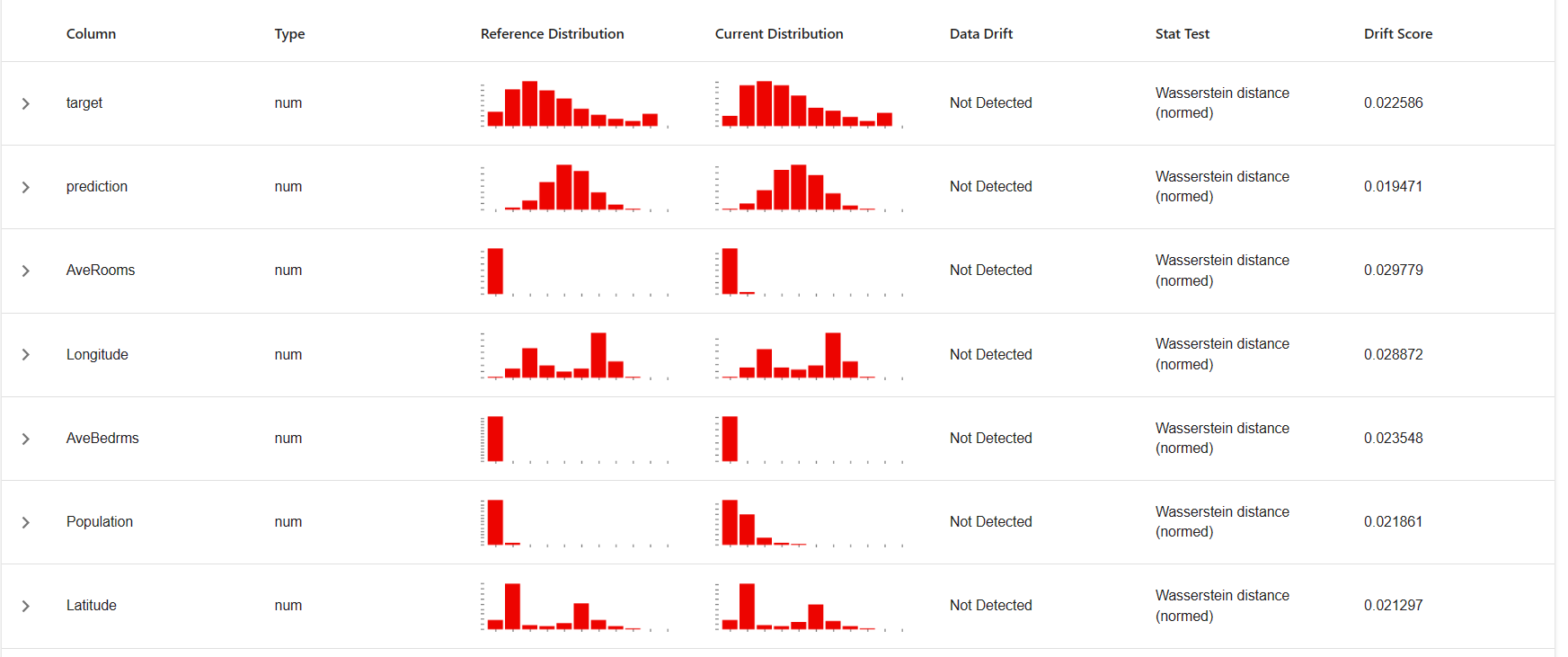
نلاحظ وجود عمود Data Drift يوضح هل هناك اي تحول في البيانات او لا, في هذا المثال لا يوجد اي تحول في البيانات وجميعها لها نفس التوزيع.
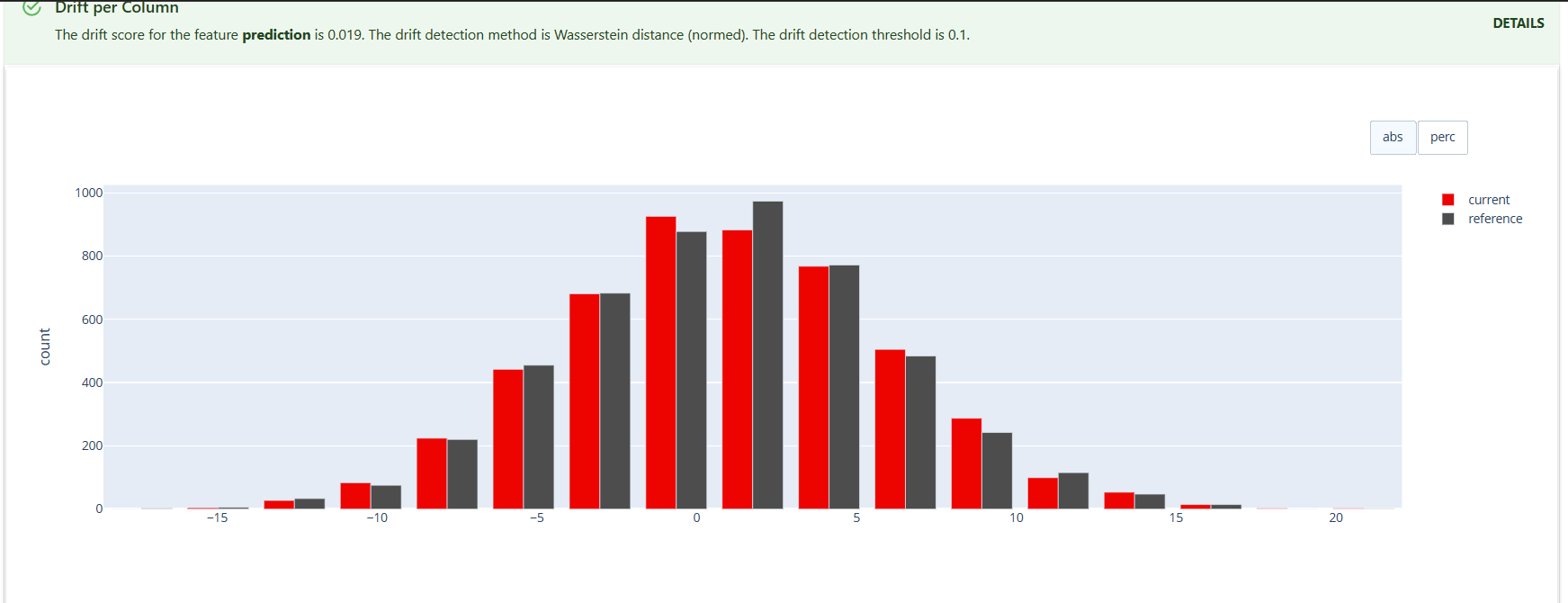
يوجد الكثير من المميزات في هذه المكتبة يمكنك الاطلاع عليها من المرجع الخاص بالمكتبة.
ختامًا
يظهر بوضوح أن فهم ظاهرة تحول النموذج محور مهم في تطوير أداء النماذج الآلية. يتأتى أهمية متابعة وتقييم البيانات بشكل دوري، وذلك من خلال استخدام أدوات مثل اختبار Kolmogorov-Smirnov ومكتبة Evidently، لمعالجة تحولات المفهوم والبيانات. التغييرات في البيئة والبيانات يمكن أن تؤدي إلى تدهور أداء النموذج مع مرور الوقت، مما يبرز أهمية تحديث النموذج بانتظام وتوفير بيانات حديثة لتعزيز قدرته على التكيف الفعّال.
في النهاية، يتعين على علماء البيانات والمطورين الاستمرار في تحسين وتطوير النماذج الآلية لضمان توافقها المستمر مع التغيرات في البيئة والبيانات. يبرز هذا أهمية استمرارية التحسين والتحديث في ميدان الذكاء الاصطناعي وعلوم البيانات لضمان استدامة أداء النماذج في ظل التحولات الدائمة في الواقع.






